

Mª Carmen López Martínez
Noelia Sayas Sánchez
I.
INTRODUCCIÓN
·
GOOGLE
·
EXCITE
·
HOTBOT
·
INFOSEEK
·
INKTOMI
·
LYCOS
·
TEOMA
·
WISENUT
Ø
CUADRO
COMPARATIVO ENTRE BUSCADORES
Ø
COMPARATIVA
ENTRE BUSCADORES SEGÚN FUNCIONES DE BÚSQUEDA
II.
METABUSCADORES:
Ø
TIPOS
Ø
ANALISIS
DE LOS METABUSCADORES:
·
CYBER411
·
DOGPILE
Ø
TABLA
COMPARATIVA ENTRE BUSCADORES Y METABUSCADORES
III.
AGENTES INTELIGENTES
Ø
TIPOLOGÍA
DE AGENTES : LA IAD COMERCIAL
·
COPERNIC
·
BULLSEYE
·
LETIZIA
Ø
INCONVENIENTES
MOTORES DE BÚSQUEDA – AGENTES INTELIGENTES
IV.
EVALUACION FINAL Y
CONCLUSIONES
Ø
EVOLUCIÓN
NUEVAS TÉCNICAS DE BÚSQUEDA EN INTERNET
El presente trabajo pretende mostrar las técnicas existentes en la
actualidad para la búsqueda de información en Internet, para ello hemos
analizado de modo general algunos de los buscadores y metabuscadores que
conviven hoy en día en la web, explicando sus características esenciales así
como sus ventajas e inconvenientes mediante el uso de tablas comparativas.
De un modo más analítico nos hemos centrado en el estudio de los
agentes inteligentes, ofreciendo una visión global de sus fundamentos aplicados
a la Inteligencia Artificial Distribuida
y hemos destacado cuatro ejemplos de agentes relacionados con las búsquedas de
información (Copernic, Bullseye, Letizia y Butterfly) mostrando las principales
características que los definen.
Hemos elaborado una tabla comparativa para observar de forma gráfica las ventajas y desventajas de los motores de búsqueda así como los agentes inteligentes.
Finalmente hemos elaborado un análisis de la evolución de las herramientas de búsqueda de información haciendo una relación y comparación entre las mismas. Hemos incluido a modo personal una conclusión enfocada hacia las perspectivas de futuro que pueden existir en las técnicas de búsqueda de información.
Internet es una fuente de información muy extensa con más de 1,200 millones de páginas y con un ritmo de duplicación que varía entre 6 y 8 meses. Las páginas provienen de ámbitos sociales diversos (instituciones oficiales, mundo académico y de investigación, particulares, etc.) y ofrecen información de todos los ámbitos del conocimiento humano.
Los
motores de búsqueda son la forma principal que permite a los usuarios de
Internet encontrar sitios con información. Esa es la razón por la cual los
sitios publicados en los listados de los motores de búsqueda incrementan dramáticamente
su tráfico. Todos quieren aparecer en los listados, desafortunadamente muchos
no lo logran por desconocer el modo en el cual trabajan los motores de búsqueda.
Existen tres tipos de motores de búsqueda, los basados en crawlers, los basados
en índices o directorios, y los meta motores de búsqueda. Estos se diferencian
por la forma como organizan la información y los enlaces a las páginas que se
encuentran en Internet. La elección del tipo de motor de búsqueda depende,
principalmente, de la necesidad de información, el número de páginas que
tienen indexadas, el nivel de actualización y un tanto de la experiencia y
gusto que se tenga sobre alguna herramienta de búsqueda en especial. Las
capacidades de búsqueda pueden construir o dividir la usabilidad de un sitio.
Las herramientas de búsqueda efectivas destacan el poder de un sitio para
transportar información.
Así
pues, los motores de búsqueda son la herramienta que permite al usuario
encontrar, de una manera sencilla, cualquier tipo de información publicada en
Internet. La información es clasificada de acuerdo a su relevancia o
importancia. Los motores de búsqueda basados en crawlers toman una serie de
criterios o parámetros incluidos en las páginas HTML para decidir que
clasificación deben darle a las páginas que indexan en Internet. La
clasificación es muy importante, ya que representa un mayor acercamiento con
los clientes, lo cual genera un sitio más accesible y exitoso.
Partes
de un motor de búsqueda:
v
Interfaz: página Web
a la que accede el usuario, pueden ser formularios o directorios.
v
Base de datos
textual: índice de palabras, frases y datos asociados con la dirección de páginas
Web (URL), programas, ficheros, etc.
v Robots: programa de ordenador diseñado para recorrer de forma automática la estructura hipertexto de la Web.
El
rápido crecimiento de disponibilidad de información como resultado del
desarrollo de la World Wide Web, lleva consigo un incremento de la complejidad
del problema de tratamiento de dicha información. Internet es demasiado grande
para la mayoría de los usuarios y a veces, puede resultar difícil encontrar lo
que se busca cuando se navega por
ella.
El éxito en las búsquedas reside en la estrategia utilizada para
localizar la información. A la hora de buscar en la Web podemos empezar con las
tres siguientes estrategias:
1-
“Adivinación” de URL
2-
Utilización de directorios
3-
Utilización de motores de búsqueda genéricos
En la tercera estrategia incluimos los buscadores que encuentran e indexan tantas páginas como les es posible de forma automática. Esencialmente son páginas web que permiten navegar al usuario en el tema que este elija, en función de cómo estén estructurados se dividen principalmente en dos tipos: clasificadores o buscadores de categorías (también conocidos como “índices”) y buscadores de contenidos (o de palabras por contexto).
Las
opciones de búsqueda de cada motor son heterogéneas ya que varían en gran
medida de unos otros en el tamaño del índice de referencia, la forma de
construir dicho índice, la ordenación de los éxitos posteriores a la búsquedas
así como el tamaño de las bases de datos. Estos motores pueden resultar útiles
para combinar palabras clave y limitarlas en campos.
Los
motores incluyen millones de páginas pero no están ni cerca de indexar todo el
Web, y qué decir de todo Internet. Algunas de las cosas que no se incluyen en
los buscadores son:
PDF
(a excepción de Google)
El
contenido de los site que requieren un password
CGI
output, como los datos solicitados mediante un formulario
Intranets.
Páginas sin enlaces desde ningún otro sitio
Sites
que utilizan robots.txt para mantenerse fuera de los motores
Recursos No Web
Las inconsistencias más patentes que se pueden encontrar en los buscadores radican en que a veces los motores de búsqueda no ofrecen los resultados que se espera que ofrezcan, en ocasiones no funcionan como se anuncia que deben de funcionan. Así mismo los buscadores más grandes sólo indexan un 30 por ciento del total de URLs disponibles y tan sólo un 0,5 por ciento del total de páginas web disponibles. La mayoría de buscadores son demasiados genéricos y la periodicidad de actualización debería incrementarse.
ALTAVISTA
http://www.altavista.com
VENTAJAS |
INCONVENIENTES |
|
Es
una de las bases de datos más grandes Tiene
potentes características de búsquedas Cobertura
internacional e interfcaes en varios idiomas |
Proporciona
resultados inconsistentes La
ordenación es por un criterio de relevancia propio únicamente Lenta
actualización de la base de datos |
Actualmente ninguna base de datos está utilizando Excite, su base de datos se
utilizó en el pasado por Netscape y AOL
VENTAJAS
|
INCONVENIENTES
|
|
Permite una
personalización recalcalble A los tópicos
más populares les asigna un número de orden más bajo (más cercano al resultado 1 de la lista de éxitos) |
Los operadores
booleanos deben estar todos en mayúsculas Tiene una base
de datos pequeña No se permite
la truncación o la búsqueda en campos |
ALL THE WEB http://www.alltheweb.com
Es una base de datos que utiliza FAST, la cual
dispone de la suya propia u no necesita de ninguna otra. De todos modos, FAST
ofrece enlaces hacia otras bases de datos específicas de MP3, FTP y multimedia,
la mayoría de ellas se alojan en Lycos
VENTAJAS
|
INCONVENIENTES
|
|
Es
un buscador grande, rápido y enfocado a localizar información únicamente No
tiene stopwords (palabras vacías) Actualización
relativamente frecuente de la base de datos Alto
grado de personalización del sistema de búsqueda |
No
es tan grande como Google y no contiene PDFs No
cuenta con copias en caché de las páginas o no pueden ser visionadas No
cuenta con truncación, operadores boléanos y la mayoría de los
restrictores a campos |
Google utiliza su propia base de datos pero
además ofrece resultados procedentes del Open Directory y de la base de datos
de RealNames. También cuenta con una colección de URLs que no han sido
indexadas como URLs duplicadas, URLs redireccionadas, páginas protegidas por un
robots.txt y páginas con accesos restringidos. Resulta difícil que aparezcan
como éxitos pero también es posible. Ofrece diferentes subconjuntos específicos:
una base de datos de .gov y .mil sites; bases de datos de búsquedas en
universidades; un buscador de Linux y uno de Mac
VENTAJAS
|
INCONVENIENTES
|
|
Es
uno de los más grandes Realiza
la ordenación de las búsquedas basándose en los enlaces de página y
“autoridad” de las que enlazan Archivo
de páginas en caché Puede
buscar la mayoría de stopwords |
Presenta
inconsistencias No
permite truncación, ni anidación y los operadores boléanos no se
permiten en su totalidad Las
búsquedas de los enlaces han de ser exactos |
Utiliza como base de datos el Open Directoty, Direct Hit e Inktomi. Si la opción de ver 10 resultados a la vez esta seleccionada, entonces los 10 provendrán de Direct Hit (si existen bastantes). En el caso de que se seleccione más resultados por página, entonces los demás provenientes de Direct Hit estarán visibles en vía link
VENTAJAS
|
INCONVENIENTES
|
|
Contiene
un formulario de búsqueda avanzada Tiene
la posibilidad de limitar la profundidad de la búsqueda Ayuda
de la búsqueda avanzada se encuentra muy detallada |
Presenta
inconsistencias Las
búsquedas de links han de ser exactas El
tamaño de la base de datos ha disminuido últimamente Los
servicios de búsqueda avanzada no siempre han funcionado bien |
INFOSEEK http://www.infoseek.com
Tiene su propia base de datos aunque también se apoya en otras bases de datos de referencia. Actualmente no es utilizada por ningún otro motor de búsqueda
VENTAJAS
|
INCONVENIENTES
|
|
Ordena
los resultados de búsqueda por site y fecha |
No
permite operadores boléanos ni limitación de campos Es
una base de datos pequeña |
INKTOMI
http://www.inktomi.com
Inktomi es la base de datos y motor de búsqueda detrás de muchos de los más conocidos motores genéricos. Provee parte de los resultados de HotBot, MSN, NBCi y Yahoo (no de los directorios). También trabaja en Go To, Won, Geocities y Anzwers entre otros. Cada partner de Inktomi utiliza sus propias opciones y parámetros, por tanto los resultados para el usuario son distintos aunque la base de datos sea la misma.
Lycos cuenta con bases de datos desde donde distribuye sus resultados.
Permite búsquedas en la guía Lycos y otras colecciones de enlaces. También
posee una versión del Open Directory que incluye modificaciones para incorporar
su catálogo invisible Web. Además ofrece búsquedas en otra base de datos de
fotografías y news. Se puede acceder a las noticias de la agencia Reuters. En
su sección de web utiliza la base de datos de Direct Hit para los
primeros
10 resultados (si los hay). La búsqueda avanzada de Lycos cambia de base de
datos y utiliza la FAST.
VENTAJAS
|
INCONVENIENTES
|
|
Vía
de acceso adicional a la base de datos de FAST Es
una gran base de datos que considera todas las fuentes Da
la posibilidad realizar una búsqueda avanzada con restrictores únicos
como frecuencia de las palabras |
No
soporta la búsqueda booleana directa A
veces el acceso a FAST ofrece una base de datos |
NORTHERN_LIGHT http://www.northernlight.com
El
motor principal busca en su gran base de datos de páginas web y en su Special
Collection. La Special Collection incluye entradas desde 5600 publicaciones como
Marklntel, Find/SVP, WEFA e Invetex así como la base de datos bibliográficas
de NTIS. Ofrece un buscador específico de temas relacionados con el gobierno de
Estados Unidos
VENTAJAS
|
INCONVENIENTES
|
|
Es
Capaz de identificar metasites Es
una base de datos nueva y original en sus criterios de construcción
basada sobre tópicos específicos |
Es
una base de datos pequeña No
dispone de las mayorías de herramienta de búsqueda avanzada
|
Cuenta con su propia base de datos que todavía solo utiliza un partner http://koreawisenut.com
VENTAJAS
|
INCONVENIENTES
|
|
Es
una base de datos nueva Capacidades
de personalización |
Se
han detectado muchas páginas repetidas No
dispone de un caché de páginas No
cuenta con la mayoría de búsqueda avanzada
|
Ø
CUADRO
COMPARATIVO ENTRE BUSCADORES
|
Buscador |
Booleano |
Proximidad |
Truncamiento |
Campos |
Límites |
Stopwords |
Ordenación |
|
All the Web |
+,
- AND |
Frase |
NO |
Título,
URL, links |
Idioma Dominio |
NO |
Relevancia |
|
Lycos |
+,
- AND |
Frase |
NO |
Título URL Links |
Idioma Dominio |
NO |
Relevancia |
|
Northern Light |
AND OR NOT () +,- |
Frase |
SI
* |
Título URL |
Tipo
Documento Fecha |
NO |
Fecha |
|
Alta
Vista (simple) |
+,- |
Frase |
SI
* |
Título URL Links |
Idioma |
SÏ |
Relevancia |
|
Alta
Vista (avanzada) |
AND, OR AND NOT () |
Frase NEAR |
SI
* |
Título URL Links |
Idioma Fecha |
NO |
Relevancia |
|
Excite |
AND OR (),
+,- |
Frase |
NO |
NO |
Idioma Dominio |
SI |
Relevancia Site |
|
Google |
AND, -, + |
Frase |
NO |
Links
relacionados |
NO |
SI |
Relevancia delas
citas |
|
Infoseek |
+,- |
Frase |
NO |
Título URL Links Site |
NO |
NO |
Relevancia Site Fecha |
|
Inktomi |
AND () +,- |
Frase |
SI
* |
Título |
Idioma Fecha |
Sí |
Relevancia Site |
|
Teoma |
+,
- |
Frase |
NO |
NO |
No |
SI |
Relevancia |
|
Hot Bot |
AND OR NOT ()
+, - |
Frase |
SI
* |
Título |
Idioma Fecha |
SI |
Relevancia |
|
Wisenut |
AND OR |
Frase |
NO
|
NO |
Idioma |
SI |
Relevancia |
Ø
COMPARATIVA
ENTRE BUSCADORES SEGÚN LA FUNCIÓN DE BÚSQUEDA
FUNCIONES
DE BÚSQUEDA
|
BUSCADORES
|
|
Búsqueda por
frase |
Alta Vista Google Lycos HotBot Northern Light |
|
Truncamiento |
Alta Vista HotBot Northern Light |
|
Texto |
Alta Vista HotBot Northern Light |
|
Imagen |
Alta Vista Hot Bot |
|
Url, dominiio,
host y país |
Alta Vista Google HotBot Lycos Northern Light |
|
Título |
Alta Vista HotBot Lycos Northern Light |
|
Links |
Alta Vista Google HotBot Lycos |
|
Idioma |
Alta Vista Google HotBot Lycos Northern Light |
II. METABUSCADORES:
Estos sistemas van más allá de los
buscadores: admiten una consulta y se encargan de lanzarla a los diferentes
sistemas de búsquedas públicos que hay en Internet. Ofrecen detalles de las
respuestas de cada uno de los servicios, o bien el listado completos de
coincidencias. Generalmente no se obtienen toda la potencia de cada uno de los
sistemas (dado que los formatos de consulta varían) pero pueden ser un buen
punto para empezar alguna búsqueda a fondo.
Los meta motores de búsqueda no contienen URLs
y descripciones en su base de datos, en lugar de eso contienen registros de
motores de búsqueda e información sobre ellos. Envían la petición del
usuario a todos los motores de búsqueda (basados en directorios y crawlers)
que tienen registrados y obtienen los resultados que les devuelven. Algunos más
sofisticados detectan las URLs
duplicadas provenientes de varios motores de búsqueda y eliminan la
redundancia, es decir solo presentan una al usuario.
·
Los sistemas de metabúsqueda van más allá de los buscadores: admiten
una consulta y se encargan de lanzarla a los diferentes sistemas de búsquedas públicos
que hay en Internet.
·
Ofrecen detalles de cada uno de los servicios, o bien el listado completo
de coincidencias.
·
Generalmente no se obtiene toda la potencia de cada uno de los sistemas
(dado que los formatos de consultas varían).
·
Pueden ser un buen punto para empezar alguna búsqueda a fondo.
·
Son intermediarios en la consulta de las preguntas. Reenvían nuestras
preguntas a uno o muchos de los buscadores más conocidos, toman las respuestas
y las clasifican nuevamente para ofrecer una respuesta unificada.
La
diferencia entre los metabuscadores es la forma de buscar, los lugares en que
buscan y cómo presentan la información.
Ø
TIPOS:
Si
hablamos de meta motores de búsqueda en general, éstos se pueden clasificar en
dos tipos, los multi buscadores y los meta
buscadores:
·
Los
multi buscadores: ejecutan la consulta
contra varios motores de forma simultánea y presentan los resultados sin más
organización que la derivada de la velocidad de respuesta de cada motor de búsqueda.
Un ejemplo es All4One.com, el cual
busca en una gran cantidad de motores de búsqueda y directorios.
·
Los
meta buscadores: funcionan de manera
similar a los multi buscadores pero, a diferencia de éstos, eliminan las
referencias duplicadas, agrupan los resultados y generan nuevos valores de
pertinencia para ordenarlos. Algunos ejemplos son MetaCrawle.com,
Cyber411.com, dogpile, y search.com.
·
En general no recogen más que las
primeras respuestas de cada buscador.
·
Utilizan un factor común de las
facilidades de búsqueda de los diferentes buscadores.
·
No podemos refinar las preguntas con
posterioridad.
·
Se limitan a búsquedas por palabras
clave.
·
Son una competencia desleal para los
otros buscadores.
·
Generalmente, tienen un tiempo de
respuesta lento, al tener que integrar los resultados obtenidos.
Busca
en AltaVista, GoTo, HotBot, FindWhat, Yahoo, Lycos, Sprinks, Knoodle, FastSearch,
MSN, Yahooligans, Ah-ha.
Asume
una búsqueda booleana con AND y soporta el AND, OR y NOT, así como el anidado.
No busca en Northern Light.
Se
puede buscar información general, investigación de comercio electrónico (e-commerce),
de empresas e incluso nombres de personas. Ofrece un servicio de registro de
sitios, que abarca más de 400 motores de búsqueda en la siguiente dirección: http://cyber411.com/submit.html.
La búsqueda se puede personalizar indicándole las bases de datos en las que
deberá buscar y el número de resultados que deberá regresar como máximo.
Presenta
un área de enlaces rápidos para la búsqueda de información, similar a los de
un directorio, en su página principal. Además de un área de productos, en la
cual se pueden comparar los mejores precios en tiendas virtuales, ayuda a
encontrar productos mediante servicios de valor añadido como valuaciones de
comerciantes, imágenes y especificaciones de productos, e información de cálculo
de precios. Entre el tipo de productos que se puede encontrar están las
computadoras, software, video juegos, música, libros, etc.
·
DOGPILE:
http://www.dogpile.com
Busca
en LookSmart, GoTo.com, Thunderstone, Yahoo, Open Directory, About.com, Lycos´
Top 5%, InfoSeek, Direct Hit, Lycos y Altavista.
Ofrece
otro tipo de servicios de búsqueda en Usenet, FTP, noticias de negocios o
generales, Stock Quotes, tiempo, páginas amarillas y blancas, y mapas. Algunos
son metabuscadores y otros son específicos.
Dogpile
nos muestra cómo se remite cada formulario de búsqueda para que podamos
detallarlo al máximo, además nos permite excluir y reordenar los motores como
queramos y provee enlaces para ver más resultados desde cada motor utilizado. No
incluye Northern Light or HotBot.
Por
último, comentar que no permite seleccionar los motores a utilizar…
·
METACRAWLER:
http://www.metacrawler.com
Utiliza Excite,
AltaVista, WebCrawler, GoTo, DirectHit, FindWhat, Google, Internet Keywords,
Kanoodle, LookSmart, MetaCatalog, Spriks. Fusiona
los resultados. Como Dogpile informa de cómo se remite cada búsqueda.
Puede
ordenar los resultados por dominio, relevancia o motor. Solo devuelve hasta 30
resultados por página y motor. Permite seleccionar el tiempo de búsqueda. No
incluye Northern Light o HotBot.
Sirve
como metabuscador por zona geográfica.
Características
importantes:
·
Cobertura
completa: al usar muchos motores, la
cobertura de la información publicada en Internet es mayor.
·
Sintaxis
de búsqueda consistente: una sola
sintaxis funciona para buscar en todos los motores registrados. Al usarla se
obtienen resultados más depurados, sin embargo la búsqueda se realiza solo en
los motores que soporten esa característica. Los operadores que soporta son: la
combinación de palabras, usando los operadores and
o + y la exclusión de palabras usando not
o -.
·
Clasificaciones
de votos de servicios: otorga una
puntuación a las páginas que regresan los motores de búsqueda, la cual es
confidencial y está normalizada de acuerdo a la importancia que la página vaya
adquiriendo, es decir, al número de veces que se le solicite en las consultas.
La puntuación varia entre 0 (la peor) y 1000 (la mejor) y se muestra casi al
final de cada resultado.
·
Opción
Power Search: permite especificar los
motores en los que se deberá buscar, el tiempo de espera por los resultados, la
cantidad de resultados por página, y el número de resultados por motor de búsqueda
fuente.
Pantalla
de búsqueda avanzada de Metacarwler.
·
SEARCH.COM:
http://www.search.com
Su operador por defecto es el AND, y da opción a búsqueda de frases.
Incluye:
Bay9, GoTo, One Search, FindWhat, Knoodle, Sprinks, Open Directory, Yahoo,
LookSmart, Teoma, mySimon, About, AskJeeves, Clearinghouse, Wisenut, Altavista,
Britannica, DirectHit, Galaxy, Hotbot, SurfPoint, Thunderstone.
Otros metabuscadores disponibles se refieren a
servicios ask an expert, precios, titulares, etc.
Solo ofrece un número bastante limitado de resultados desde cada
buscador. Tampoco incluye el Northern Light.
Presenta un área de temas clasificados en la forma como lo hace un
directorio y un área de canales referentes a temas como linux,
gobierno, noticias, horóscopo, etc. Se pueden personalizar las categorías de
la búsqueda, así como los motores que serán incluidos en la meta búsqueda,
los cuales están clasificados de acuerdo a su área (noticias, compras, etc.),
además, las opciones pueden definirse para futuras sesiones.
TABLA
METABUSCADORES:
|
Service |
Basic Boolean? |
|
Yes |
|
|
Yes |
|
|
Yes |
|
|
Yes |
|
|
Yes |
TABLA
COMPARATIVA ENTRE BUSCADORES Y METABUSCADORES:
|
Buscadores
|
Metabuscadores |
|
Bases
de datos más amplias y actualizadas. |
No
tiene bases de datos propias, sino que buscan automáticamente en las de
otros buscadores. |
|
|
No
almacenan información porque no dependen de bases de datos propias. |
|
No
realizan las búsquedas en Internet "en vivo", sino en las
copias de las páginas que almacenan en sus índices. |
|
|
Son
más difíciles, se requiere explotar al máximo las opciones de búsqueda
porque contienen más información. |
Son
difíciles de usar para búsquedas muy precisas, porque tienen menos
control de la búsqueda al interrogar varias bases de datos con
interfaces diferentes. |
|
Se
utilizan para buscar información más escasa, especializada,
actualizada o incluida en páginas personales. |
Se
recomienda para temas "oscuros", difíciles de encontrar. |
La inteligencia artificial distribuida (IAD) se ha definido como un
subcampo de la Inteligencia Artificial (IA) que se centra en los comportamientos
inteligentes colectivos que son productos de la cooperación de diversas
entidades denominadas agentes. A pesar de tratarse de una disciplina joven,
podemos destacar tres períodos cronológicos diferenciados:
-
La
IAD “Clásica” se centra en el estudio de la conducta colectiva, en oposición
a la IA, que estudia la conducta individual
-
La IAD “autónoma” se centra en el
estudio de los agentes individuales situados en un mundo social.
-
La IAD “comercial” se centra en la
combinación de la IAD clásica y autónoma, desarrollando agentes (denominados
genéricamente agentes software) con características muy diferenciadas
(agentes móviles, personales..) que están siendo explotados de forma
comercial.
Moulin
y Chaib-draaa distinguen cuatro áreas de trabajo de la IAD:
-
La
perspectiva de grupo, que estudia los elementos que caracterizan a un grupo de
agentes, su comunicación e interacciones
-
La perspectiva de agente, que incluye
todos los elementos que caracterizan a un agente, la cual ha sido desarrollada
siguiendo las divisiones de la IAD autónoma y comercial
-
Perspectivas específicas, que recogen
las relaciones de otros campos con la IAD
-
La perspectiva del diseñador, que
recoge los métodos, técnicas de implementación, bancos de prueba,
herramientas de diseño y aplicaciones de la IAD.
En
nuestro caso nos vamos a centrar en la perspectiva del agente en donde la
denominada IAD autónoma se centra en los microaspectos de la IAD, es decir, en
los agentes inteligentes, más que en los macro-aspectos (tratados en la IAD clásica).
Dichos aspectos se dividen en cuatro áreas: teoría de agentes, arquitectura
de agentes, lenguajes de agentes y su tipología.
Se trata de especificaciones para
conceptuar los agentes. Debido a que la definición de agente ha resultado ser
tan controvertida como la definición de inteligencia artificial, se ha optado
por una definición de un conjunto de propiedades que caracterizan a los
agentes, aunque un agente no tiene que poseer todas estas propiedades:
Describen
la interconexión de los módulos software/hardware que permiten a un agente
exhibir la conducta enunciada en la teoría de agentes. Frente a otras tecnologías
con componentes fijos como la de objetos (atributos y métodos) o la de sistemas
expertos (motor de inferencias, base del conocimiento y otros elementos
opcionales) en los agentes nos encontramos con una gran variedad de
arquitecturas. Atendiendo al tipo de procesamiento empleado se pueden clasificar
las arquitecturas en deliberativas, reactivas e híbridas.
Arquitecturas deliberativas:
Siguen la corriente de la IA simbólica, basada en la hipótesis de los sistemas
de símbolos-fsiicos de Newell y Simons, según la cual un sistema de símbolos
físicos es capaz de manipular estructuras simbólicas para exhibir una conducta
inteligente. Las arquitecturas de agentes deliberativos se basan en la teoría básica
de planificación de la IA: dado un estado inicial, un conjunto de
operadores(planes y un estado objetivo, la deliberación del agente consiste en
determinar qué pasos debe encadenar para lograr si objetivo, siguiendo un
enfoque descendente (top-down).
Dentro
de la arquitectura deliberativa se distinguen los agentes intencionales, capaces
de razonar sobre sus carencias e intenciones y los agentes sociales, agentes
intencionales que mantienen un modelo explícito de otros agentes y son capaces
de razonar sobre estos modelos.
Arquitecturas
reactivas :
Cuestionan la viabilidad del modelo simbólico y proponen una arquitectura que
actúa siguiendo un enfoque conductista, con un modelo estímulo-respuesta Para
ello siguen un procesamiento ascendente (botto-up) para lo cual mantienen una
serie de patrones que se activan bajo ciertas condiciones de los sensores y
tienen un efecto directo en los actuadores. Las principales arquitecturas
reactivas son:
·
Reglas situadas: la implementación más
sencilla de reactividad se basa en la definición del comportamiento con reglas
del tipo si situación-percibida entonces acciones especificas
·
Arquitectura de subsunción y autómatas
de estado finito: permiten gestionar problemas de mayor complejidad que las
reglas. Esta arquitectura esta compuestas por capas que ejecutan una determinada
conducta (Ej. evitar un obstáculo). La estructura de cada capa es la de una red
de topología fija de máquinas de estado finitas. Las capas mantienen una
relación de inhibición sobre las capas inferiores (inhibir entradas de los
sensores y acciones en los actuadores). El control no es central, sino dirigido
por los datos en cada capa.
·
Tareas competitivas: Un agente debe
decidir que tarea debe realizar entre varias posibles, seleccionando la que
proporciona un nivel de activación mayor. Se basa en una aproximación ecológica
del problema de resolución distribuida de problemas que se resuelve sin
comunicación entre los individuos, estableciendo un criterio de terminación
del problema. Por Ej. los problemas clásicos de búsqueda (mundo de los
bloques) se interpretan como agentes 8cada bloque) que pueden realizar
movimientos y una condición global de terminación.
·
Redes neuronales: la capacidad de
aprendizaje de las redes neuronales también se ha propuesto en algunas
arquitecturas formadas por redes capaces de realizar una función 8evitar
colisiones etc.).
Arquitecturas
híbridas:
Se basan en la combinación de aspectos deliberativos y reactivos
interrelacionando módulos reactivos, encargados de procesar los estímulos que
no necesitan deliberación, con los módulos deliberativos, que determinan qué
acciones deben realizarse para satisfacer los objetivos locales y cooperativos
de los agentes. Estas arquitecturas pueden ser horizontales (Touring Machines)
y verticales (PRS e Interrap).
Se
definen como lenguajes que permiten programar agentes con los términos
desarrollados por los teóricos de agentes. Se distinguen dos tipos principales
de lenguajes de programación:
En
cuanto a programación de agentes se pueden distinguir los siguientes:
·
Lenguajes de programación de la
estructura del agente: permiten programar
las funcionalidades básicas para definir un agente: creación de procesos y
comunicación entre agentes (nivel de transporte)
·
Lenguaje de comunicación de agentes:
definición del formato de los mensajes intercambiados, de las primitivas de
comunicación y delos protocolos disponibles
·
Lenguajes de programación del
comportamiento del agentes: permiten
definir el conocimiento del agente: conocimiento inicial (modelo de entorno,
creencias, objetivos), funciones de mantenimiento de dicho conocimiento (reglas,
planes etc.), funciones para alcanzar sus objetivos (planes, reglas, etc.) y
funciones para desarrollar habilidades (programación de servicios).
·
COPERNIC http://www.copernic.com

Copernic
Agent
es un agente de búsqueda implementado por copernic.com,
una empresa que data de principios de 1996 y que ha desarrollado desde su
comienzo tecnologías de agentes para la gestión y acceso eficiente a la
información existente en Internet e intranets. Esta organización tiene como
fin encontrar modos de reducir el tiempo que los navegadores emplean en realizar
operaciones complejas y repetitivas y conseguir que puedan ejercer su trabajo
mediante las nuevas tecnologías de la información de forma amigable.
Copernic
Agent
es una nueva línea de productos que reemplazan la anterior línea conocida como
Copernic 2000/2001 mediante una renovación completa de su arquitectura e
interfaz. Copernic ofrece tres productos informáticos que permite consultar de
manera simultánea varios motores de búsqueda predeterminados y fuentes de
información en la Web.
Este agente de búsqueda presenta categorías para determinar los motores apropiados a usar con el fin de obtener mayor precisión. Por otro lado elimina resultados duplicados, verifica y suprime vínculos rotos, destaca palabras clave en la lista de resultados y en las páginas Web, guarda páginas para navegación fuera delinea y encuentra palabras clave en resultados o en las páginas Web con operadores boléanos.
En
Copernic Agent se mantiene un histórico detallado de búsqueda que
permite al usuario visualizar y manipular los resultados en función de sus
necesidades de información, pudiendo actualizar después las búsquedas
realizadas. Presenta una actualización automática del programa y de los
motores de búsqueda, permitiendo el acceso al soporte técnico en el sitio Web
de Copernic e incluso el envío de sugerencias para mejorar el producto.
Este agentes de búsqueda tiene extensiones para Windows y otros programas,
especialmente para Internet Explorer, integrando muchas herramientas nuevas de
exploración. La extensión más útil para el navegador es una barra multi-función
que da la posibilidad de realizar un seguimiento de palabras clave en las páginas
Web usando una función que destaca y desplaza botones, crea nuevas búsquedas y
señala la trayectoria de cambio en las páginas.
Copernic
Agent Basic es
gratuito y no tiene fecha de vencimiento. Presenta siete categorías: La Web
(dispone de dos categorías una de lenguaje o una basada en el país que se
elija entre una lista de 14), grupos de noticias, direcciones electrónicas,
compra de libros, compra de equipos informáticos y de programas.
Aproximadamente se pueden acceder a unas 80 fuentes de información.
Copernic
Agent Personal
y Copernic Agent Profesional, ofrecen aproximadamente 125 categorías
para realizar las consultas, ofreciendo un acceso a más de 1200 motores de búsqueda,
estas dos versiones, además de tener todas las funciones de la versión
gratuita, permiten realizar una verificación ortográfica sobre las palabras
claves escritas, filtrar los resultados y agruparlos de diferentes formas. También
se puede crear categorías de búsquedas favoritas y personalizadas así como
agregar nuevas. En el caso de Copernic Agent Personal puede eliminar los
vínculos rotos, mientras que Copernic Agent Profesional puede extraer
conceptos fundamentales de las páginas Web, detectar páginas duplicadas en
direcciones que no son idénticas y resumir el contenido de del resultado de las
páginas Web encontradas, así mismo ofrece una función de seguimiento que
rastrea de forma automática los cambios de las páginas y actualiza las búsquedas
específicas mediante el envío de informes por correo electrónico.
o
Sistema operativo : Windows
95/98/ME/NT4/2000/xp con Internet Explorer 4.0 SPT (o superior)
o
Navegador: Internet Explorer 4.0,
Netscape navigator/communicator 4.x o 6.x opera el navegador predefinido del
programa o cualquier otro compatible
o
CPU: Pentium 120 MHZ o más rápido
o
RAM: 32 MB (mínimo)
·
Barra de búsqueda rápida para
facilitar la creación de la búsqueda
·
Los resultados encontrados se califican
y se despliegan en función a su relevancia
·
Las listas de resultados obtenidos se
pueden organizar y agrupar de diferentes formas, según la versión que el
usuario tenga instalada
·
Posibilidad de personalizar el formato
o diseño de los resultados
·
Permite la opción de realzar las
palabras claves en los resultados y en las páginas Web utilizando un motor de
color único o de color múltiple
·
Existencia de una barra de filtro con múltiple
características avanzadas, principalmente están disponibles en las versiones
comerciales
·
Existencia de una barra de resultados
obtenidos para buscar palabras específicas en las listas de resultados y en las
páginas Web
·
Eliminación de los resultados
irrelevantes seguido del análisis de las páginas que contienen las palabras
clave u operadores lógicos (esta característica solo aparece en Copernic
Agent Profesional)
·
Eliminación automática de vínculos
duplicados
·
Las páginas coincidentes se pueden
descargar para una navegación fuera de línea y para encontrar palabras a través
de palabras clave o de operadores lógicos
·
Las búsquedas realizadas se pueden
modificar, actualizar, duplicar y agrupar en carpetas y sub-carpetas
·
Los reportes de búsqueda se pueden
exportar o enviar por correo electrónico en diferentes tipos de archivos
·
Ofrece muchas extensiones para Windows,
Microsoft Office e Internet Explorer
·
Posibilidad de detectar páginas
duplicadas con diferentes direcciones (esta función es única en Copernic
Agent Profesional)
·
Posibilidad de automatizar tareas con
las versiones comerciales: Verificar y borrar vínculos rotos o no localizables,
descargar páginas y perfeccionar resultados (Únicamente Copernic Agent
Personal puede automatizar la validación del vínculo)
·
Ofrece la posibilidad de crear categorías
personalizadas y favoritas con las categorías y los motores existentes (Esta
función sólo es válida para las versiones de Copernic Agent Personal y
Copernic Agent Profesional)
·
Posibilidad de abstraer conceptos clave
de las páginas Web y resumir su contenidos en los resultados obtenidos (Esta
función sólo es válida para las versiones de Copernic Agent Personal y
Copernic Agent Summarizer)
·
Agrupación de los motores de búsqueda
y fuentes de información bajo categorías en función de su especialización
·
Las categorías de búsqueda se agrupan
en dominios de interés para realizar la selección con mayor facilidad
·
Posibilidad de contactar hasta 32
fuentes de información de forma simultánea para la búsqueda de resultados,
verificar vínculos rotos y extraer datos de páginas Web y páginas descargadas
·
Su historial de búsqueda detallado e
ilimitado permite el seguimiento de follow-ups
·
Posibilidad de detectar idiomas de las
páginas (se requiere la versión Copernic Agent Profesional)
·
Posibilidad de extraer conceptos
fundamentales de páginas web para desplegarlos en la lista de resultados (se
requiere la versión Copernic Agent Profesional)
·
Posibilidad de actualizar las búsquedas
para encontrar nuevos resultados
·
Posibilidad de modificar y duplicar los
parámetros de búsqueda para realizar una búsqueda similar e incrementar la
precisión
·
Posibilidad de
mover y copiar las búsquedas de una carpeta a otra
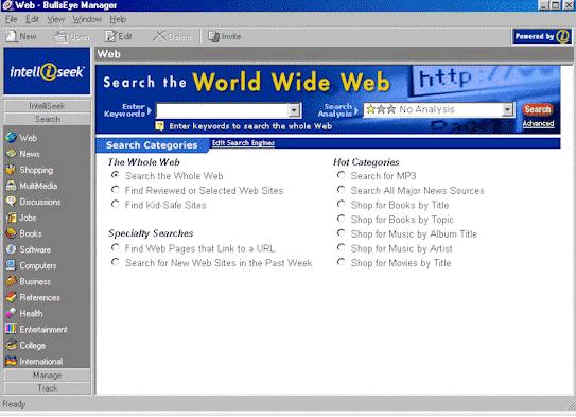
En primer lugar diremos que en la página http://www.intelliseek.com/prod/bullseye.htm
podemos encontrar (si no presenta errores de página) otro agente de búsqueda
comercial, tan potente como el anteriormente descrito: Copernic; se trata de
IntelliSeek Bullseye 3.
Bullseye 3.0 ofrece una amplia cobertura de búsqueda en la web (más de
1.000 motores de búsqueda), además permite que mires tus resultados y navegues
al mismo tiempo.
Este agente de búsqueda te da un rápido acceso a respuestas relevantes,
ofrece áreas de búsqueda especializadas que te llevan a la información que
necesites y resalta tus términos de búsqueda en las correspondientes páginas
web.
FICHA TÉCNICA BULLSEYE
3.0:
|
Descargas:
2.413 |
|
Idioma:
Inglés |
|
Sistema Operativo:
Windows 2000, Windows 95,
Windows 98, Windows
Me,Windows NT, Windows XP |
|
Tamaño del archivo:
8.63 MB |
|
Licencia:
Demo |
|
Empresa:
IntelliSeek |
|
Información de
contacto:
info@intelliseek.com
|
|
Precio:
BullsEye Plus v3.0: 49 $
BullsEye Pro v3.0: 199 $ |
|
Fecha actualización:
19 Marzo 2002 |
EMPRESA
PRODUCTORA:
La tecnología de IntelliSeek está realizando un
magnífico trabajo en el tratamiento de la información en Internet, sus
herramientas ayudan a la gestión de la información que los usuarios quieren
encontrar en la red. IntelliSeek es una empresa privada cuya infraestructura está
basada en Internet. Se consideran la empresa líder en búsqueda inteligente
para la web, y han sido reconocidos y premiados por su labor en búsquedas
inteligentes.
La empresa desarrolla productos con una tecnología
única de agentes inteligentes que ayudan al usuario a encontrar y gestionar sus
búsquedas (sean del tipo que sean: compras, noticias…). Ofrece soluciones a
pequeñas empresas así como también a grandes corporaciones que buscan ser las
mejores respecto a la competencia en lo que se refiere a su aparición en la
Web.
IntelliSeek ofrece cuatro soluciones para encontrar
información en la Web:
1.
Profusion.com:
proporciona una búsqueda inteligente, es una herramienta que busca en otros
motores para obtener unos resultados iniciales y luego utiliza IA (Inteligencia
Artificial) para decidir y procesar entre los resultados obtenidos aquellos que
son más relevantes.
2.
BullsEye:
es un buscador web que permite la organización de la información para que la búsqueda
en Internet sea precisa.
3. BullsEye Pro: además de las funciones de BullsEye, incorpora una característica adicional: búsqueda guiada que permite seleccionar las fuentes a utilizar y especificar tiempos de búsqueda.
4. InvisibleWeb.com: servidor web gratuito donde los usuarios pueden buscar en una amplia colección de bases de datos invisibles.
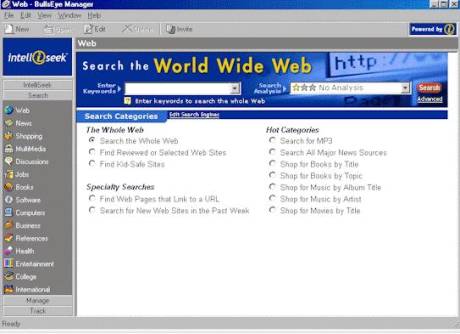
CARACTERÍSTICAS
DE BULLSEYE:
·
Búsqueda
de sitios web por países específicos; incluyendo USA, Canadá, los países Nórdicos,
Reino Unido, Rusia, India, Australia, México, Colombia y otros lugares de América
Latina.
·
Añade o cambia motores de búsqueda fácilmente.
·
Al realizar una pregunta a BullsEye obtienes respuestas rápidas en
lenguaje natural.
·
Permite el acceso a más de 100 motores de búsqueda.
·
Tienen amplios recursos de búsqueda en una única aplicación (más de
1.000 en BullsEye Pro y más de 800 en BullsEye Plus).
·
La integración “SurfSaver” permite que tengas una copia permanente
de las páginas web, guardando dichas páginas con el formato y la capacidad
adecuados para buscar un website incorporando funcionalmente arañas.
·
Dispone de diferentes tipos de búsqueda que se dividen en las siguientes
categorías: la cobertura en la web, búsquedas especializadas y ficheros u
objetos especiales.
·
También dispone de traductor de búsqueda, acceso a sites con Bases de
datos, corrector ortográfico, análisis lingüístico avanzado y cronómetro.
·
Su manejo es fácil y el diseño amigable e intuitivo.
·
El idioma que utiliza es el inglés.
·
Elimina enlaces rotos, duplicados o irrelevantes.
·
Estudia la consulta introducida mediante un análisis lingüístico
avanzado.
·
Permite una búsqueda especializada por áreas usando tecnologías de
agentes de búsqueda.
·
Ahorra visitar páginas que no son útiles y evita la furstración de no
encontrar lo que se busca.
·
Permite ojear los documentos rápidamente para comprobar su validez.
·
Contiene áreas de empresas de informática, noticias y asistencia técnica;
área para encontrar FAQ (preguntas más frecuentes); agente de compras que
permite comparativa, pues encuentra precios, disponibilidad e información sobre
las empresas que venden productos por Internet; opciones de personalizar los
resultados obtenidos.
·
BullsEye Tracker (característica exclusiva de BullsEye Pro) para
localizar información en el site, página o ítem; o localiza cuáles son las
novedades en un rango de fecha específico. Después recibes correos electrónicos
o alertas cuando la información cambia.
·
Organiza los resultados de búsqueda por conceptos y refina y filtra la búsqueda.
Para
describir el agente de búsqueda Letizia hay que contextualizarlo en lo que se
denominan agentes de interfaz. Estos agentes acentúan la autonomía y el
aprendizaje para realizar las tareas de sus usuarios. Esencialmente, los agentes
de interfaz utilizan y proporcionan ayuda típicamente a un usuario que aprende
a utilizar una aplicación determinada tal como una hoja de cálculo o un
sistema operativo.
Un
agente de usuario observa y vigila las acciones tomadas por el usuario en la
interfaz, aprende de nuevos “short-cuts” y sugiere mejores maneras de hacer
la tarea. Así, este tipo de agente actúa como ayudante personal autónomo, que
coopera con el usuario para lograr una cierta tarea en la aplicación. En cuanto
a lo que aprendizaje se refiere, los agentes del interfaz aprenden a mejorar su
ayuda al usuario de cuatro maneras:
Observando e imitando al usuario
Con
la recepción del feedback positivo y negativo del usuario
Recibiendo
instrucciones explícitas del usuario
Pidiendo consejos a otros agentes
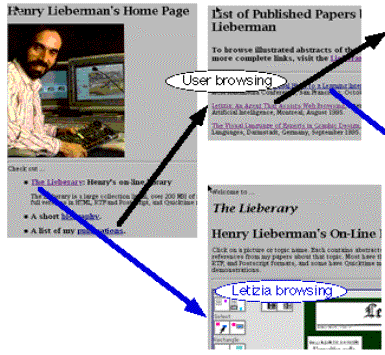
Letizia es un agente de reconocimiento de información para la Web. Opera desde un navegador convencional, como Netscape. Mientras el usuario lee una página, Letizia realiza una simple búsqueda en anchura, previsualizando los vínculos de la página en cuestión. Se encuentra continuamente proporcionando recomendaciones de páginas al usuario. Utiliza un cierto mecanismo de aprendizaje para actuar en función de los gustos del usuario. Observa su comportamiento e intenta inferir sus intereses automáticamente. Almacena todas las elecciones realizadas por el usuario en el hecho de que esa página le resulta interesante al usuario. Dinámicamente, Letizia, aplica una variante de TFID sobre los textos de las páginas visitadas, y el resultado lo usa para modificar el modelo de usuario que utiliza. Un simple cálculo de frecuencia de palabras claves se usa para analizar las páginas, como medida de recuperación de la información.
Usa la propia interfaz de Netscape para presentar sus resultados, en una ventana independiente en que el agente señala las páginas que probablemente podrán interesar al usuario. La interfaz usual de Letizia consiste en tres ventanas de Netscape. Por defecto, la ventana de la izquierda ser reserva para el usuario el cual puede navegar en esa ventana de manera normal ignorando cualquier actividad del agente. Otras dos ventanas menores, situadas al lado derecho – una arriba de la otra- están bajo el control del agente. Lo exhibido en la ventana de arriba es una búsqueda de candidatos, paginas cuya recomendación evalúa. La ventana inferior derecha muestra las páginas que Letizia decide recomendar realmente al usuario, pasadas las pruebas que aplica para verificar su interés. El usuario puede escoger continuar su navegación en las páginas seleccionadas o bien elegir en cualquier momento las sugerencias del agente, para ello el usuario debe simplemente conectarse a la ventana que contiene una página recomendada por Letizia y seguir navegando, así mismo puede colocar las páginas recomendadas en una hotlist o como lo hace de costumbre en Netscape.
Si bien los buscadores ofrecen un gran número de páginas sin conexión
Letizia utiliza la propia conexión de las páginas mediante los links a una página
dada que conforman una especie de vecindad semántica de dicha página, así
busca en las páginas vecinas
intercalando una búsqueda en
anchura con una búsqueda en profundidad con lo que se incrementa la
probabilidad de conseguir resultados relevantes.
El papel de Letizia es el de una guía. Cuando los usuarios activan su
browser favorito, deben indicar sus intereses explícitamente al usar los
motores tradicionales de búsqueda. Tanto el usuario como los motores de búsqueda
permanecen estáticos mientras que se mira la interfaz. Esencialmente Letizia
proporciona una búsqueda cooperativa entre sí mismo y el usuario. Mientras que
la mayoría de browsers realizan una búsqueda en profundidad, Letizia conduce
una búsqueda en paralelo para otras direcciones útiles, haciendo una conjetura
de las intenciones de los usuarios y deduciendo su comportamiento al navegar.
En agentes autónomos como Letizia la revisión de la Web tanto navegando como buscando información es reemplazarla por una revisión de la Web navegando como una actividad en tiempo real. La meta no es de ningún modo obtener una “mejor respuesta”, sino hacer mejor uso posible del recurso más limitado y valioso: la atención de usuario.
En primer lugar, diremos que Internet permite la creación
descentralizada a gran escala de comunidades virtuales y de contenidos informáticos.
Además, se caracteriza por tener una estructura no lineal. Una característica
general de los interfaces de búsqueda de información, es que deben ser activos
en la identificación de objetos de interés.
Butterfly sirve de modelo de interés para el usuario como canal de
prueba, pues recomienda canales a medida que descubre nuevos canales de interés
para el usuario. Además es un interfaz que cubre toda la arquitectura de
Internet y su contenido.
Los principales obstáculos que debe superar Butterfly son:
·
Trata con miles de canales simultáneos de conversación en tiempo real.
·
Son grupos creados ad-hoc.
·
Estar enfocado al Internet Relay Chat (IRC).
·
Existe gran dificultad para encontrar grupos de interés.
Un ejemplo habitual de uso de Butterfly podría ser el siguiente: un
usuario necesita información sobre comercio electrónico, agentes y comunidades
de software: para localizar esta información el usuario entra en contacto con
el buscador Butterfly y éste le recomienda el canal VirSoc (en el que a menudo
discuten sobre comunidades de software). Más tarde, Butterfly lo conecta al
canal Havhav en el que se discute sobre agentes.
CARACTERÍSTICAS:
·
El
interés de Butterfly radica en que los contenidos están modelados por palabras
clave y vectores de términos; los perfiles están explicados específicamente.
·
Butterfly admite distintos soportes como TfiDF, LSI, etc.
·
Los pesos asignados a los términos de contenido se basan en la
frecuencia de la aparición.
·
Basado en una arquitectura existente y en convenio o expectativas
sociales, así como en un amplio horario de visita (10 canales a la vez). También
extiende los términos-vectores después de cada visita; suprimiendo los valores
anteriores y conservando los nuevos después de cada visita.
·
Butterfly es muy interactivo, pues usa el IRC para enviar mensajes de
usuario a usuario.
·
Es
un interfaz de lenguaje pseudonatural; además responde al usuario
inmediatamente y asigna notificaciones sobre conversaciones actuales de interés.
Podemos extraer las siguientes conclusiones acerca de
Butterfly:
¨
Ayuda a encontrar nuevos canales útiles, es un tipo de interfaz activo
en la web.
¨
Muchos canales están escondidos, por lo que la circulación se hace difícil.
INCONVENIENTES DE LOS MOTORES DE BÚSQUEDA Y LOS AGENTES INTELIGENTES
|
|
MOTORES
DE BÚSQUEDA
|
AGENTES
INTELIGENTES DE INFORMACION |
|
I
N C O N V E N I E N T E S |
§
Poca precisión en las búsquedas §
A medida que aumenta la información en
Internet decrece la cobertura de información §
No es capaz de adaptarse al usuario
puesto que no se basa en el perfil del mismo §
Dificultad en el refinamiento de las búsquedas §
Constituyen bases de datos relativamente
estáticas §
Carecen de capacidad para interconectar
hipervínculos §
El interfaz del usuario responde a la
manipulación directa: el ordenador es pasivo y espera siempre ejecutar
las instrucciones del usuario §
En ocasiones no funcionan como se
anuncian que deben funcionar §
Los buscadores más grandes sólo
indexan un 30% de las urls y tan sólo un 0.5% del total de páginas web
disponibles §
La mayoría son demasiado genéricos §
La periodicidad de actualización debería
incrementarse §
No incluye elementos de la web invisible
: PDF (excepto Google), contenido de site que requieren pasword, CGI
output, como datos solictados mediante un formulario (.asp), intranets,
sites que utilizan robots .tx. para mantenerse furea de los motores y
recursos no web §
Carecen de autonomía, inteligencia,
adaptabilidad, sociabilidad, iniciativa, continuidad y habilidad
cooperativa |
§
Existe muchas lagunas a nivel conceptual §
No todos los agentes poseen las
propiedades que un agente debería tener (autonomía, sociabilidad,
capacidad de reacción, iniciativa, adaptabilidad, continuidad, movilidad,
veracidad, benevolencia y cooperación §
Número reducido de motores de búsqueda
a consultar en las versiones gratuitas e imposibilidad de ampliar §
Gran consumo de recursos, tanto a nivel
de máquina de usuario, como a nivel de uso de prestaciones en la red §
Problemas de comunicación entre agentes
a causa de la personalización de los mismos §
Complejidad para mantener y crear un
agente en cada una de las bases de datos en la red §
Problemas de seguridad derivados de la
capacidad de movilidad, puesto que pueden inferir en aspectos privados de
los usuarios |
La gran cantidad de información disponible en forma on-line a través de
Internet puso de manifiesto la necesidad de proveer a los usuarios de
herramientas que facilitaran la navegación y búsqueda en este vasto espacio de
información. Desde la aparición de la World Wide Web a principio de los
años noventa, el incremento de los usuarios de Internet se ha disparados
exponencialmente de tal modo, que según las previsiones de crecimiento de la
red, se calcula que el número de páginas web se duplica cada 173 días. Este
hecho, que en principio puede ser una de las ventajas que nos ofrece la red, se
convierte también en su inconveniente principal, ya que el crecimiento de
usuarios conlleva a un aumento de la información que desborda la capacidad de
recuperación.
Para solventar este inconveniente han ido apareciendo a lo largo de esta década diferentes herramientas o técnicas
de búsqueda que evitan al usuario vagar sin rumbo por la red para localizar la
información que necesita. En principio, y debido a la inexistencia del web estas máquinas de búsquedas se
basaban e el protocolo FTP, como es el caso de Archie, la primera máquina de búsqueda
en Internet. Con la creación y difusión del web en 1993 se desarrollaron las
herramientas de búsqueda en Internet más populares y más utilizadas en la
actualidad, estas aplicaciones denominadas buscadores se han implantado en la
web de tal forma que es prácticamente imposible consultar una dirección sin
utilizarlas. Los buscadores, también llamados herramientas de primera generación
(Aguillo 1998), se han convertido en la puerta de acceso a Internet de la gran
mayoría de los usuarios que buscan información. Los motores de búsqueda
brindan, mediante una interfaz simple basada generalmente en palabras clave, el
acceso a un gran número de documentos Web. En un principio, los sistemas
expertos se diseñaron para ejecutar consultas en una única base de datos pero
la propia idiosincrasia de Internet ha hecho que aparezcan miles de bases de
datos almacenadas en diferentes direcciones. Esta simplicidad para expresar
requerimientos de información usualmente conlleva pobres niveles de precisión
en los resultados obtenidos a partir de ellos. Esto implica que el usuario debe
aplicar una considerable cantidad de tiempo y esfuerzo en revisar o navegar a
través de una lista ordenada de documentos, donde normalmente varios de ellos
no son de su interés, antes de encontrar información verdaderamente relevante.
Por otro lado, su funcionamiento es bastante inflexible, ya que la máquina de búsqueda
se encuentra en un ordenador remoto al que hay que acceder como cliente, de modo
que la búsqueda se debe adaptar a las normas del servidor.
A medida que la red ha ido creciendo y evolucionando se ha acrecentado de manera
notable la forma de localizar y consultar la información on-line, así mismo
cuando se incrementa la información en la web decrece paralelamente la
cobertura ofrecida por los buscadores, por lo que los resultados de las búsquedas
no son los esperados, ya que la mayoría de herramientas disponibles para
localizar y recuperar la información se centran más en la cantidad que en la
calidad informativa por lo que se convierten en muchas ocasiones más que en una
fuente de información en una fuente de frustración.
Pese a que los buscadores como hemos visto, ofrecen sus ventajas, actualmente la
gran cantidad de buscadores existentes hace prácticamente imposible tener
conciencia de todos ellos y conocerlos en profundidad, de ahí nacieron los
metabuscadores, unos sistemas que van más allá de los buscadores, ya que
admiten una consulta y se encargan de lanzarla a los diferentes sistemas de búsquedas
públicos que hay en Internet. Ofrecen detalles de las respuestas de cada uno de
los servicios, o bien el listado completo de coincidencias. Generalmente no se
obtiene la potencia de cada uno de los sistemas (dado que los formatos de
consultas varían) pero pueden ser un buen punto para empezar a realizar alguna
búsqueda a fondo. El nacimiento de los metabuscadores fue un paso más allá en
lo que a técnicas de información se refiere, las ventajas esenciales que
ofrecen se basan en el acceso a una sola página web para formular la búsqueda,
se necesita sólo conocer la interfaz de una página para realizar la consulta,
se formula un única vez la estrategia de búsqueda y se obtienen resultados
integrados, a partir de varios buscadores. Así mismo el hecho de que los
metabuscadores no dispongan de sus propias bases de datos sino que interroguen
las de otros buscadores, significan una importante reducción de los costos por
concepto de hardware para los productores. Ciertamente , esta podría ser una
causa para el auge de los metabuscadores y su aceptación entre los navegantes.
Los principales problemas que plantea los metabuscadores se basan en que
resultan totalmente imposible que estas herramientas puedan unificar todas las
ventajas de cada uno de los motores y que, por consiguiente, las búsquedas
booleanas pueden generar resultados diferentes en diversos buscadores, las búsquedas
por frases pueden que no se ejecuten en alguno de ellos, y otros elementos como
el uso de limitadores pueden sacrificarse.
Para
intentar solventar estos y otros problemas han aparecido en los últimos años
las denominadas herramientas de segunda generación o Agentes Inteligentes. El
primer inicio de estos agentes inteligentes lo tenemos en una aplicación
desarrollada por Cahrles River Analytics Inc en 1993 llamada Open
Sesame! Que corría en una máquina Apple. Aunque su función no
tienen ninguna relación con la búsqueda de información, se puede considerar
el antecesor de todos los agentes inteligentes que se encuentran hoy en día en
el mercado. Esta herramienta ayudaba al usuario a usar su ordenador de la forma
más productiva y tenía cierta capacidad de aprendizaje.
En
la actualidad se han desarrollado cientos de agentes inteligentes que asisten
activamente al usuario proporcionándole información personalizada mientras
navega o realiza sus actividades normales en la web, principalmente consiste en
delegar algunas de las tareas de búsqueda, recuperación, organización y
representación de la información, hasta ahora del ser humano, en un software
que actúa en representación del usuario. Una de las aplicaciones de estos
agentes consiste en la ruptura del cuello
de botella que se produce en el desarrollo de aplicaciones a la hora de generar una base de conocimientos sobre la que
trabaje dicha aplicación.
Dentro del área de la Inteligencia Artificial los agentes han
tomado gran protagonismo entre los investigadores, un área que tiene
limitaciones y ambigüedades a nivel conceptual, las cuales se ven incrementadas
cuando el contexto en el que estamos tratando es ese cajón desastre de
información llamado Internet.
Básicamente un agente inteligente de información es un sistema software de
computación que tiene acceso a múltiples y heterogéneas fuentes de información
que están distribuidas geográficamente. Las ventajas son numerosas ya que son
programa que se instalan en el ordenador del usuario de forma que este posee un
mayor control sobre su funcionamiento. Son herramientas capaces de aprender, de
colaborar, de programarse de hacer búsquedas off-line, se basan en la facilidad
del uso, en el incremento de productividad y precisión en la búsqueda y en la
reducción de sobrecarga que generan los procesos de búsqueda en Internet y en
el propio sistema.
Theodore Roszak cuenta en su libro “El culto a la información” que no
siempre fue la información un valor por el que se mostrara un interés
desmesurado. Incluso en la primera mitad del siglo XX, pocos la hubieran
concebido como objeto de una teoría o una ciencia. Mil millones de segundos y
bits después, el mundo se constituye sobre la base de la información.
Actualmente la red es el lugar donde nos cabe palpar una nueva era de información.
La red abre la puerta a un mundo global, y nos muestra sus múltiples regiones.
La red es memoria también, se dice que es la memoria colectiva de la humanidad.
Bits como luces de un ciberespacio que se atraviesa navegando los mares de
información. Memoria de hechos, datos, situaciones, fechas, lugares. Pero la
red no recuerda, la red no sabe que sabe. La lectura crítica de la información
será entonces el mayor logro de la práctica profesional y en este contexto
Internet y la web proveen de un excelente medio para cultivar y desear esta
habilidad.
La búsqueda de información en la Web ha sufrido crisis en los mecanismos
tradicionales: los crawlers ya no dan abasto para indexar la enorme cantidad de
páginas disponibles ; la naturaleza dinámica de la Web contrasta con el
planteamiento estático de este modelo ; el concepto de relevancia ya no basta
para presentar al usuario los mejores documentos en primer lugar, todo ello
realzado con los problemas de índole económica: spamming y publicidad.
La búsqueda pertinente de información en la presenta, a nuestro modo de ver,
un futuro incierto. Actualmente los buscadores están incorporando herramientas
propias de los agentes inteligentes, que consiste en una personalización del
buscador para adaptarlo a las necesidades del usuario. El futuro de los medios
de recuperación de información en Internet pasa por la generalización de las
ventajas que ofrecen los agentes inteligentes, de manera que lo más probable es
que los buscadores evolucionen y añadan a sus utilidades los avances que
ofrecen los agentes inteligentes.
Podríamos decir que el uso de los buscadores es como una cadena que va desde lo
más general a lo más específico. Los metabuscadores se utilizan generalmente
para temas muy difíciles o cuando no existe idea alguna de los beneficios de
uno u otro buscador. Los buscadores se emplean casi siempre en los inicios del
uso de Internet, cuando el navegante tiene solo algún conocimiento sobre ellos,
bien para buscar temas en los que no se ha investigado con frecuencia o muy
particulares que suelen encontrarse en los directorios temáticos. En la medida
en que crezca la cultura de Internet y la experiencia de los navegantes, estos
dejarán de recurrir a los buscadores en beneficio de la creación de la marca y
se identificarán más con los portales que se adecuen a sus necesidades de
información.
La red avanza y no espera a nada ni a nadie, es obvio que los agentes de información son la última tecnología en cuanto a técnicas de información se refiere pero aún es un área en ciernes que tiene que evolucionar y mejorar en esa ventana al mundo imparable como es la web, si bien los agentes inteligentes están revolucionando notablemente el modo de trabajar de los usuarios, por mucho pasos que de siempre estará por detrás del crecimiento exponencial informativo. Lo que hoy es actualidad mañana puede ser historia.
- AGENTES AUTÓNOMOS. Disponible en: <URL: http://www.puc.cl/infsecic/boltec10/letizia.html> [Acceso 5 de agosto 2003]
- AGENTES DE SOPORTE LÓGICO (software agentes) 5 agentes de interfaz. Disponible en: <URL http://club2.telepolis.com/ohcop/nw05.html> [Acceso 5 de agosto 2003
-
AGUILAR GONZÁLEZ, Rogelio: “Monografía sobre motores de búsqueda”.
Disponible en:
<URL:
http://www.geocities.com/motoresdebusqueda/inicio.html>. [Acceso 16 de
julio 2003].
-
ALL THE WEB. Disponible
en: <URL: http://www.altheweb.com>.
[Acceso 15 de julio 2003]
-
ALTAVISTA. Disponible en <URL: htpp://www.altavista.com>.
[Acceso 15 de julio 2003].
-
BULLSEYE. Disponible en: <URL: http://www.intelliseek.com>.
[Acceso 18 julio 2003].
-
BUTTERFLY. Disponible en: <URL:
http://www.neilvandyke.org/butterfly/>. [Acceso 18 julio 2003].
-
COPERNIC. Disponible en: <URL: http://www.copernic.com>.
[Acceso 18 de julio 2003].
-
CORNELLA Alfons: “Desarrollo de buscadores”. En: El
profesional de la información, vol.
9, nº 1-2 (en.-feb. 2000).
-
CYBER411. Disponible en: <URL: http://www.c4.com>.
[Acceso 15 de julio 2003].
-
DOGPILE. Disponible en: <URL: http://www.dogpile.com>.
[Acceso 15 de julio 2003].
-
EXCITE. Disponible en: <URL: http://www.excite.com>.
[Acceso 15 de julio 2003].
-
GOOGLE. Disponible en: <URL: http://www.google.com>.
[Acceso 15 de julio 2003].
-
HÍPOLA, Pedro ; VARGAS-QUESADA, Benjamín: “Agentes Inteligentes: Definición
y tipología. Los agentes de información”. En: El
profesional de la información, vol. 8, nº 4 (abr. 1999).
-
HÍPOLA, Pedro ; VARGAS-QUESADA, Benjamín: “Descripción y evaluación de
agentes multibuscadores”. En: El
profesional de la información, vol. 8, nº 11 (nov. 1999), p. 15-26.
-
HOT BOT. Disponible en: <URL: http://www.hotbot.com>.
[ Acceso 15 de julio 2003].
-
IGLESIAS FERNANDEZ, Carlos Ángel: “Fundamentos de los Agentes
Inteligentes”.Informe técnico UPM/DIT/GSI 16/97. Disponible en: <URL: http://
www.iti.uned.es/superior/cuarto/ docs/Apuntes>. [Acceso 17 de julio 2003]
-
INFOSEEK. Disponible en: <URL: http://www.infoseek.com>.
[Acceso 16 de julio 2003].
-
INKTOMI. Disponible en: <URL: http://www.inktomi.com>.
[Acceso 16 de julio 2003].
-
LETIZIA. Disponible en: <URL: http://lcs.www.media.mit.edu/people/lieber/lieberary/Letizia/Letizia-Intro.html
-
LIEBERMAN, Henry: “Autonomous Interface Agents”. Disponible
en: URL:http://lcs.www.media.mit.edu/people/lieber/Lieberary/letizia/AIA/AIA.html.
[Acceso 17 de julio 2003]
-
LYCOS. Disponible en: <URL: http://lycos.es>.
[Acceso 16 de julio 2003]
-
METACRAWLER. Disponible en: <URL: http://www.metacrawler.com>.
[Acceso 17 de julio 2003].
-
MORENO ROMERO, Francisco Javier: “Pasado, presente y futuro de la recuperación
de información en Internet”. En:
DoIS (Documents in Information Science).
Disponible en:
<URL:
http://168.143.67.65/congreso/ponencias/ponencia-4.pdf>. [Acceso 19 de
agosto 2003].
-
NORTHERN LIGHT. Disponible en: <URL: http://www.northernlight.com>.
[Acceso 16 de julio 2003]
-
SEARCH.COM. Disponible en: <URL: http://www.search.com>.
[Acceso 16 de julio 2003].
-
TEOMA. Disponible en: <URL: http://www.teoma.com>.
[Acceso 16 de julio 2003].
-
TORRES POMBERTL, Ania (2003): “El uso de los buscadores en Internet”.
Disponible en:
<URL:
http://www.infomed.sld.cu/revistas/aci/vol11_3_03/aci04303.htm>. [Acceso
13 de agosto 2003].
-
TRAMULLAS SANZ, Jesús ; Olvera Lobo, Mª Dolores: “Recuperación de la
información en Internet”. Madrid: Ra-Ma, 2001.
-
USO DE BUSCADORES EN INTERNET. Disponible en: <URL: htpp://www.infomed.sld.cu/revistas/aci/vol11_3_03/aci04303.htm>.
[Acceso 17 de julio 2003]
-
WISENUT. Disponible en: <URL: http://www.wisenut.com>.
[Acceso 16 de julio 2003].