|
WEB INFERENCIAL
Inés Coronel Català Andrés García Cano Jorge Rodríguez Guilabert |
|
|
|
|
|
1. INTRODUCCIÓN |
|
|
La Web Semántica se puede entender como un proyecto de reorganización o reformulación de las bases de la web. Decir esto no aclara ningún concepto, por lo que una definición más aclaratoria sería que la Web Semántica es un proyecto que tiene la intención de dotar a la web de “significado”, es decir dotarla de una semántica accesible a las máquinas. Por esta razón el objetivo principal de este proyecto es lograr que las máquinas puedan entender y por tanto utilizar, lo que la web alberga. De esta forma, la Web Semántica no es una nueva Web, es una extensión de la Web actual en la que la información se presenta con un significado bien definido, permitiendo a los ordenadores y a las personas trabajar conjuntamente Este proyecto surge, entre otros, de manos de Tim Berners-Lee, uno de los ideadores-creadores de la WWW, como respuesta a la situación en la que se encuentra la web y como un intento de solución a los problemas que el vertiginoso crecimiento y desarrollo de la red han generado: sobrecarga de información y heterogeneidad de las fuentes de información. La Web semántica propone superar las limitaciones de la web actual mediante la introducción de descripciones explícitas del significado, la estructura interna y la estructura global de los contenidos y servicios disponibles en la WWW. Para realizar esta labor se utiliza un concepto de la Inteligencia Artificial: la Ontología, que se combina con los metadatos. Una ontología es una jerarquía de conceptos con atributos y relaciones, que define una terminología consensuada para definir redes semánticas de unidades de información interrelacionadas. Una ontología proporciona un vocabulario de clases y relaciones para describir un dominio, poniendo el énfasis en la departamentación del conocimiento y el consenso en la representación de éste. La idea es que la web semántica esté formada por una red de nodos tipificados e interconectados mediante clases y relaciones definidas por una ontología compartida por sus distintos autores. La adopción de ontologías comunes es clave para que todos los que participen de la Web Semántica, agregando o consumiendo recursos, puedan trabajar de forma autónoma con la garantía de que las piezas encajen.
Para la realización de estas tareas se utilizan, esencialmente, dos estándares: - RDF (Resource Description Framework).- Es un lenguaje para la definición de ontologías y metadatos en la web, cuya forma sintáctica más conocida es la basada en XML. - OWL (Web Ontology Language) surge de la fusíon de otros dos lenguajes OIL (Europeo) y DAML (Americano) y se puede formular en RDF. De esta forma incluye toda la capacidad expresiva de RDF y la extiende con la posibilidad de utilizar expresiones lógicas y permite atribuir ciertas propiedades a las relaciones, como cardinalidad, simetría, transitividad o relaciones inversas.
Si bien RDF y OWL son hoy en día los lenguajes más consolidados, existen otros lenguajes interesantes, aunque con menos usuarios, como TopicMaps, OCML o WebODE.
Pero para que todo este proyecto de semantización de la Web sea útil es necesario que exista una estructura de trabajo (framework) que permita explicar tareas del razonamiento de la Web Semántica almacenando, intercambiando, combinando, abstrayendo, anotando, comparando e interpretando las demostraciones (proofs) y los fragmentos de demostraciones proporcionados por los reasoners (razonadores) embebidos en los servicios y aplicaciones de la Web Semántica. Y, que además, sea capaz de permitir este trabajo de manera integrada, manteniendo y permitiendo la hetereogeneidad de los diferentes sistemas. Este marco es la Inference Web (IW), que se espera que sea lo bastante flexible como para atender las necesidades de explicación de una amplia audiencia de usuarios de la Web Semántica. De esta forma es la IW la que le otorga accesibilidad, usabilidad y trasparencia a la Web Semántica, para que los usuarios (los seres humanos y los agentes) que deben utilizar e integrar las respuestas del sistema puedan confiar en esta. Esta “Declaración de confianza”, por parte de los usuarios se alcanza haciendo demostraciones fáciles de visualizar y proporcionando demostraciones que usen notaciones “centradas en el usuario". La interoperabilidad se alcanza haciendo demostraciones (y fragmentos de la demostración) con capacidad de ser compartidas, fáciles de distribuir y combinar, y libre de inexplicadas reglas de inferencia de reasoners-específicos. La reutilización se alcanza haciendo demostraciones capaces de ser anotadas o comentadas además de hacerlas interoperables. Por esta razón, las herramientas que se integran en el marco de la IW deben conseguir que sus “productos” o demostraciones cumplan ciertos requisitos técnicos como:
- Información de la procedencia.- Deben explicar la localización de la fuente de información: nombre de la fuente, fecha y autor de la última actualización, autor/es de la información original, tasa del grado de confianza, etc. - Información del razonamiento.- Deben explicar el origen de la información derivada: reasoner usado, método de razonamiento, reglas de inferencia, asunciones, etc. - Generación de la explicación.- Deben proporcionar las descripciones abreviadas de la demostración pudiendo incluir, dependiendo de la clase del Lenguaje de representación (e.g., DAML+OIL, OWL, RDF...), axiomas que capturan la semántica, reescritura de las reglas basadas en axiomas, otras técnicas de la abstracción, etc. - Despliegue distribuido basado en web de demostraciones - construcción de demostraciones que sean portátiles, con capacidad de ser compatidas y combinables, que se puedan publicar en múltiples clientes, registro disponible en web y potencialmente distribuido... - Presentación de Demostración/explicación - la presentación debe tener porciones (pequeñas) gestionables que sean comprensibles por si solas (sin el contexto de una demostración entera), los usuarios deben estar apoyados en sus peticiones de explicaciones y se deben responder sus preguntas, los usuarios deben conseguir de forma automática y personalizada demostraciones acotadas (podadas), opción de navegador web, múltiples formatos, personalizable, etc.
La solución que, en estos momentos, plantea la IW incluye un registro extensivo que contiene detalles de las fuentes de información y los razonadores empleados, una explicación detallada de las demostraciones, que además es portátil (puede tener una Compilación en diferentes plataformas y en cualquier Sistema operativo) y un navegador de la explicación (an explanation browser.)
Como veremos en los siguientes puntos la framework de la IW contiene los siguientes elementos:· Datos.- Se usan para representar demostraciones, explicaciones y meta información sobre esas demostraciones y explicaciones. · Herramientas software y servicios.- Se usan para construir, mantener, presentar y manipular las demostraciones.
|
|
|
|
|
|
2.1. DATOS IW proporciona el PML, que se basa en OWL (Web Ontology Language). Expresado en términos de clases, la clase PML es una subclase de la clase OWL. Este lenguaje se usa para construir documentos OWL que representen a la vez demostraciones junto con información de su procedencia. Los conceptos PML pueden ser conceptos del nivel de demostración (proof level concepts) o conceptos del nivel de procedencia (provenance level concepts).
Las demostraciones y explicaciones de la Web Inferencial se representan mediante documentos construidos en PML usando elementos de demostración y haciendo referencia a elementos de su procedencia. Los documentos en PML se convierten en una porción de los datos de la Web Inferencial usados para combinar y presentar demostraciones y para generar explicaciones.
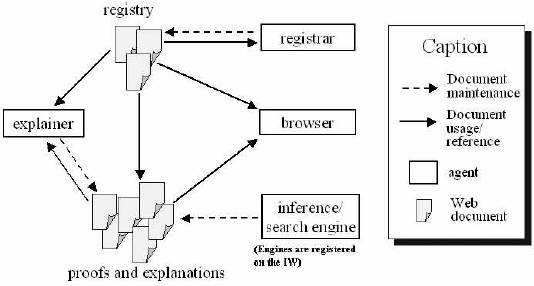
Figura1 - vista general del framework
La Figura 1 muestra una vista general del framework de la Web Inferencial con demostraciones y explicaciones en la web. Los datos de la Web Inferencial también incluyen un repositorio distribuido de documentos PML que representan la meta información relacionada con cada demostración. Las descripciones de PML incluyen información de la procedencia de demostraciones concretas (proof elements) tales como fuentes, motores de inferencia y reglas de inferencia. IW Base es una infraestructura dentro del framework de la Web Inferencial para la meta información de las descripciones.
Elementos de demostración en PML Hay 2 componentes principales para construir árboles de demostraciones: Sistema de nodos (NodeSets) y pasos inferenciales (InferenceSteps).
Node Sets e Inference Steps La figura 2 presenta un vaciado típico de un NodeSet. Un NodeSet representa un paso (step) en una demostración cuya conclusión es justificada por cualquier paso (step) del sistema (set) de pasos inferenciales (InferenceSteps) asociados al NodeSet. PML adopta el término "sistema de nodos"(node set) puesto que cada instancia del NodeSet se puede ver como un sistema de nodos recolectados de uno o más árboles de demostración que tienen la misma conclusión. La propiedad iw:hasConclusion de un NodeSet representa la expresión concluida por el paso (step) de la demostración. Cada NodeSet tiene una conclusión, que se representa en el lenguaje especificado en la propiedad iw:hasLanguage del NodeSet. En el ejemplo, la conclusión del NodeSet indica que el color de WINE9 es ?x
Figura 2 – Un PML NodeSet
En general, cada NodeSet puede estar asociado a uno o múltiples pasos inferenciales (InferenceSteps), como aparece en la propiedad iw:isConsequentOf del NodeSet de la Figura 2. Una demostración puede ser entonces definida como un árbol de pasos inferenciales (InferenceSteps) que van explicando el proceso de deducir el consecuente. En términos del número de archivos, una demostración puede variar físicamente de un único archivo en PML que contenga todos sus NodeSets a muchos archivos en PML, conteniendo cada uno un NodeSet. Además, los archivos en PML que contienen NodeSets se pueden distribuir en web. En vista del requisito de IW de que las demostraciones han de ser combinables, es importante acentuar que un set de los NodeSets es un bosque de árboles de demostraciones puesto que cada NodeSet puede tener múltiples InferenceSteps y cada InferenceStep es una justificación alternativa para la conclusión del NodeSet. El URI (Uniform Resource Identifiers) de un nodeSet es el unico identificador del NodeSet. Cada NodeSet tiene un URI bien formado Cada NodeSet tiene una conclusión, y una conclusión de un NodeSet es de tipo Expresión (Expression) La expresión del lenguaje (ExpressionLanguage) de un NodeSet es el lenguaje en que la conclusión se ha representado. Cada NodeSet tiene una expresión de lenguaje, que es de tipo ExpressionLanguage Cada InferenceStep de un NodeSet representa la aplicación de una regla de inferencia que justifica la conclusión del NodeSet. Cada NodeSet tiene al menos un InferenceStep, y cada InferenceStep de un NodeSet es de tipo InferenceStep. Los InferenceSteps son clases anónimas definidas mediante NodeSets. Por esta razón, se asume que las aplicaciones que manejan demostraciones PML están capacitadas para identificar el NodeSet de un InferenceStep. Además, es por esta razón que los InferenceSteps no tienen URIs
Para una demostración de IW, un InferenceStep es una aplicación simple de una regla de inferencia. Las reglas de inferencia (por ejemplo, el modus ponens) se pueden usar para deducir una conclusión de cualquier número de antecedentes (que son las conclusiones de otros NodeSets). Los InferenceSteps contienen referencias a los NodeSets que concluyen sus antecedentes, la regla de inferencia usada y las fuentes de la justificación. No hay fuente asociada al NodeSet en la figura 2 puesto que es derivado (aunque podría ser derivado y ser asociado a una fuente). Si hubiera sido afirmado, tendría que haber sido asociado a una fuente, que es normalmente la ontología que lo contiene. El antecedente en un InferenceStep puede venir de las conclusiones en otros NodeSets, de ontologias existentes, de la extracción de documentos, o pueden ser suposiciones.
Con respecto a una pregunta, los puntos de partida lógicos para un sistema de NodeSets de PML son los NodeSets que concluyen los enunciados de la respuesta a la pregunta. Cualquier NodeSet se puede presentar como soporte solo y ser un fragmento significativo de la demostración ya que contiene por lo menos un InferenceStep, y cada uno de sus InferenceSteps tiene la regla de inferencia usada junto con links a sus antecedentes, a las fuentes y a las ligaduras (binding[1])variables[2]. La infraestructura de IW puede generar automáticamente la cadena de preguntas para cualquier fragmento de la demostración preguntando cómo ha sido derivado cada enunciado antecedente. Los fragmentos individuales de la demostración pueden ser combinados juntos para generar una demostración completa, es decir, un sistema de InferenceSteps que culminan en los InferenceSteps que contienen solamente antecedentes afirmados.
Elementos de procedencia en PML Los elementos de procedencia se usan para proporcionar información sobre los componentes que se han usado en una demostración. Cada entrada en IW Base es una instancia de un elemento de procedencia en PML. El motor de inferencia (InferenceEngine), el lenguaje (Language), y la fuente (Source) son los elementos básicos de procedencia.
El InferenceEngine es un concepto esencial puesto que cada InferenceStep debe tener un link al menos a una entrada al motor de inferencia responsable de instanciarlo. Por ejemplo, la figura 2 muestra que la propiedad iw:haslnferenceEngine de iw:InferenceStep es un puntero a JTP. - owl, que es meta información de IW Base sobre el probador de teoremas JTP de la Universidad de Stanford. Los motores de inferencia actualmente pueden tener las siguientes propiedades asociadas a ellas: nombre, URL, autor(es), fecha, número de versión, organización, etc. La lista de propiedades puede ampliarse conforme se vayan demandando.
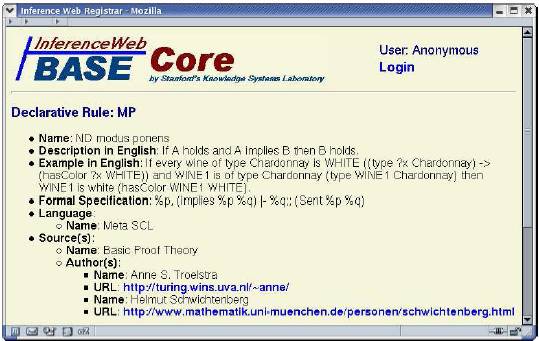
InferenceRule es uno de los conceptos más importantes asociados al motor de inferencia. Las reglas de inferencia dicen básicamente a un usuario o agente qué clase de operaciones puede realizar un motor de inferencia particular. Con respecto a un motor de inferencia, las reglas registradas pueden ser primitivas o derivadas de otras reglas registradas. La figura 3 muestra un interfaz del navegador (browser) de IW que presenta la entrada para la regla modus ponens (M.P.). El M.P. puede ser una regla primitiva para un determinado motor de inferencia. Cada regla de inferencia puede incluir un nombre, una descripción, un ejemplo opcional, y una especificación formal opcional. La figura 3 muestra que la regla de inferencia M.P. se puede especificar formalmente por la secuencia "%p, (implica %p %q) |- %q;; (Sent %p %q)" que se escribe en el protocolo de demostraciones para el razonamiento deductivo (PPDR). Así, el significado de la regla M.P. viene de la semántica de PPDR y de la especificación M.P. en PPDR. Dada una regla: tiene "%p" e "(implica %p %q)" como premisas; “%q" como conclusión; y "(Sent %p %q)" como parte de la condición. Por otra parte, las premisas y la conclusión son patrones del enunciado puesto que utilizan metavariables (por ejemplo, %p y %q). La parte de la condición (side condition) “(Sent %p %q)” dice que los argumentos %p y %q usados en las premisas y la conclusión se pueden limitar a un enunciado.
Figura 3 – Una entrada en IW Base para una regla de inferencia
Para registrar formalizaciones de una regla de inferencia La Web Inferencial no tiene un estándar de lenguaje específico para formalizar reglas de inferencia. Con PML, IW proporciona un mecanismo para registrar especificaciones de la regla y los lenguajes usados para ello. En el ejemplo del M.P. la regla se escribe en PPDR, que es un lenguaje para describir las reglas usadas en las demostraciones donde las conclusiones se escriben en KIF. Cualquier instanciación válida de las premisas y la conclusión del M.P. son enunciados válidos en KIF. PPDR es una opción conveniente para la especificación de la regla puesto que fue diseñado para este propósito y la Web Inferencial lo entiende, de manera que le permite dar servicios de abstracción de la demostración. No es la única opción que puede ser registrada – las reglas se pueden especificar en otros lenguajes también. La desventaja de registrar en otros lenguajes es que las herramientas de IW, como los comprobadores de demostraciones (proof checkers), puede que no proporcionen tantos servicios si son lenguajes que las herramientas no pueden entender.
Declarative Rules y Method Rules La experiencia de la Universidad de Stanford especificando reglas primitivas en IW ha demostrado que una proporción significativa de ellas puede ser formalizada completamente usando un lenguaje específico para declarar reglas como PPDR. PML denomina a estas reglas que pueden ser totalmente formalizadas DeclarativeRules. Las reglas que no pueden ser completamente formalizadas se llaman MethodRules puesto que las reglas de esta categoría pueden necesitar confiar en un método adicional para decidir si un paso de la inferencia (InferenceStep) basado en ellas es una aplicación válida de la regla. Para las reglas del método, además de la formalización, PML permite el registro del método y del lenguaje usado para escribir ese método.
Utilizando Un razonador para explicar Reglas de Inferencia de otros Muchos razonadores (reasoners) también utilizan un sistema de reglas derivadas que pueden ser útiles para la optimización u otras cosas que conciernen a la eficiencia. Un razonador particular no puede proporcionar una demostración de ninguna regla derivada particular, pero puede señalar a la demostración de otro razonador de una regla. Así, las reglas de un razonador específico se pueden explicar en el IW Base antes de que el razonador se utilice realmente para generar demostraciones en PML. De esta forma, la Web Inferencial da una manera de utilizar un razonador para explicar las reglas de inferencia de otros razonadores. Esta estrategia puede ser útil para explicar los motores de inferencia fuertemente optimizados. Puede también ser útil para las situaciones donde se sabe que un método de razonamiento es mejor para un tipo de explicación que otro. IW Base contiene en la actualidad sistemas de reglas de inferencia para muchos sistemas comunes de razonamiento. Los usuarios pueden visionar sistemas de reglas de inferencia para ayudarles a decidir qué motor de inferencia usar. IW Base contiene hoy sistemas de reglas para JTP, para DAML/OWL, SNARK, JSAT, el mediador de ISI, y diez de los motores del extractor de UIMA de la IBM. También tiene sistemas parciales de reglas para algunos otros razonadores.
Los motores de inferencia pueden utilizar axiomas especializados de un lenguaje para dar soporte a lenguajes como OWL o RDF. Language es un concepto de base de IW Base. Los axiomas se pueden asociar a un lenguaje. El sistema de axiomas se puede utilizar como fuente y las reescrituras especializadas de esos axiomas se pueden utilizar por un demostrador (prover) de teoremas para razonar con más eficiencia. De esta manera, las demostraciones pueden depender de estos sistemas de axiomas específicos de un lenguaje, que en la Web Inferencial se llaman LanguageAxiomSets. Una entrada de Language puede estar asociada a varias entradas de LanguageAxiomSet de la misma manera que varios razonadores pueden encontrar diversos sistemas de axiomas para ser más útiles. Por ejemplo, JTP utiliza un sistema horn-style de axiomas DAML para su razonador de DAML mientras que otro razonador puede utilizar un sistema distinto por cuestiones de eficiencia, estilísticas, de interoperabilidad, o por razones de la presentación. También, una entrada de un axioma puede estar incluida en entradas múltiples de LanguageAxiomSet. El atributo content de las entradas del axioma indica el lenguaje especificado por el atributo del lenguaje del axioma.
La fuente es el otro concepto base de IW Base y es un elemento de procedencia puesto que se utiliza para identificar el origen de un fragmento de información. La fuente se especializa en cinco clases básicas: Persona, equipo, publicación, Ontología[3] (Ontology), organización (Organization) y Sitio Web (Website). Las entradas de Ontology, por ejemplo, describen almacenes de aserciones que se pueden utilizar en demostraciones. Se puede presentar información como la fuente de la ontología, fecha, versión, URL (para navegar), etc. IW utiliza ontology en un sentido amplio e incluye en IW Base, dentro de éste término, modelos conceptuales, información individual, las bases de conocimiento y los modelos del dominio. La figura 4 muestra una entrada del registro de ontology
Figura 4 – Una entrada en IW Base para una Ontología
|
|
|
|
|
|
2.2. SOFTWARE
Las herramientas de IW incluyen:
IW Base es una red interconectada de repositorios distribuidos de demostraciones y de explicaciones de meta información. Cada repositorio de la red es un nodo de IW Base que reside en un servidor web. Un nodo de IW Base es un URI (Uniform Resource Identifiers) en el servidor web, que contiene un documento OWL de un elemento de procedencia. El contenido de cada nodo URI de IW Base también se refleja en un sistema (set) de la base de datos. Por lo tanto, las demostraciones de PML pueden tener acceso directo a su meta información resolviendo sus referencias de URI con las entradas de IW Base.
El Nodo Registro (registrar) y los Servicios Los servicios de nodo de IW Base, sin embargo, pueden necesitar maneras más sofisticadas de preguntar a las entradas ya que puede que no sepamos exactamente qué entrada recuperar, por ejemplo, cuando un usuario de IW Base necesita navegar por las entradas de un nodo. En estos casos, los servicios pueden aprovecharse del sistema subyacente de la base de datos para preguntar por las entradas del nodo. Por ejemplo, para interactuar con IW Base, cada nodo proporciona una colección de servicios que se llaman a la vez mediante un nodo registrador (registrar) que da soporte a los usuarios para actualizar o navegar por el registro. El registro (registrar) puede actualizar o dar privilegios de acceso sobre un elemento de procedencia base y el administrador del nodo puede definir e implementar políticas de acceso al nodo de IW Base. La generación de fragmentos de demostración es una tarea directa una vez que las estructuras de datos del motor de inferencia, que almacenan demostraciones particulares (elementos) se identifican como componentes de IW. Para facilitar la generación de demostraciones, IW Base proporciona un sistema de servicios web basados en SOAP[5] que descargan demostraciones desde componentes de IW y suben (upload) componentes de IW desde demostraciones. Este servicio es una facilidad que proporciona la independencia de lenguajes que se usa para descargar demostraciones. También, es un mecanismo valioso para registrar el uso de las entradas de IW Base.
Nodo de Base (Core Node) y Nodos de Dominio (Domain Nodes) Además de las propiedades genéricas de los nodos de IW Base descritos arriba, la arquitectura de IW Base especifica que cada nodo es un nodo de base (core node) o un nodo de dominio (domain node). De hecho, algunos elementos de procedencia como el motor de inferencia, la regla de inferencia y el lenguaje son tan genéricos que puede ser apropiado reunirlos en un solo nodo, el nodo de base (core node), que está también disponible públicamente para los otros nodos de IW Base. La arquitectura del nodo de base es conveniente cuando hay un sistema de entradas que describen la meta información principal sobre motores comunes, sus reglas, y los lenguajes de representación y razonamiento.
Nodo de colaboración La arquitectura de IW Base también especifica algunos servicios que apoyan la colaboración entre nodos. Los servicios básicos para hacer copias locales de las entradas de nodo son proporcionados por un repositorio concurrente de la versión del sistema (Concurrent Version System - CVS[6]) donde se almacena el URI del OWL. Usando los servicios de CVS, los usuarios pueden chequear copias personales de otras entradas de nodo (ya sean entradas de nodo base o de dominio) y almacenarlas localmente. Parece ser que los administradores de nodos de dominio prefieren guardar las copias locales del nodo base por motivos de eficiencia y/o privacidad. Hay servicios más sofisticados para interactuar con nodos de dominio. Por ejemplo, el administrador de un nodo de dominio (supongamos un nodo especializado con meta información sobre ordenadores portátiles) puede especificar que el nodo guarda relación con otro nodo del dominio. Así pues, si un nodo del dominio para ordenadores portátiles puede sacar beneficio reutilizando una cierta meta información que ha sido ya almacenada en un nodo del dominio sobre ordenadores en general, puede utilizar ese nodo. Estos servicios entre los nodos de dominio también dan una solución al problema de decidir dónde almacenar la meta información sobre las denominadas “ontologías de nivel superior” (upper level ontologies). De hecho, sube hasta los usuarios de otro nodo del dominio para decidir si desean reutilizar la meta información sobre otras ontologías y qué les gustaría incluir. IW Base proporciona un soporte para la información de procedencia a nivel de bases de conocimiento y de ontologías.
Abstractor API de demostraciones Aunque esenciales para el razonamiento automatizado, las reglas de inferencia como las usadas por los demostradores (provers) de teoremas y registradas en IW Base como entradas de InferenceRule son a menudo inapropiadas para explicar tareas de razonamiento. Por otra parte, las manipulaciones sintácticas de las demostraciones basadas en reglas de inferencia atómicas pueden también ser insuficientes para abstraer demostraciones generadas por máquina y convertirlas en demostraciones algo más comprensibles. Las demostraciones, sin embargo, pueden ser abstraídas cuando se reescriben usando reglas derivadas de axiomas y de otras reglas. Los axiomas en las reglas de reescritura son los elementos responsables de reconocer patrones y de proporcionar las versiones abstraídas y reescritas de las reglas. Las entradas de DerivedRule son las candidatas naturales a almacenar sistemas especializados de reglas de reescritura. En IW, la táctica se lleva a cabo mediante reglas de reescritura asociadas a axiomas, y se usan independientemente de si una regla es atómica o derivada. El algoritmo del abstractor de demostraciones genera explicaciones de una manera sistemática usando reglas derivadas de IW Base. Muchos resultados intermedios son “soltados" (dropped) junto con sus axiomas de soporte, abstrayendo la estructura de demostraciones cuando se aplica el algoritmo. El resultado general es que se ocultan las reglas del razonador de base y se exponen las abstracciones de las reglas derivadas de alto nivel. La implementación del abstractor API de demostraciones es un trabajo que todavía están realizando en la Universidad de Stanford.
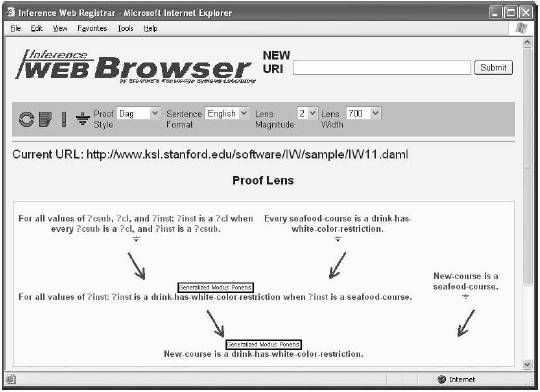
La Web Inferencial incluye un navegador que puede presentar a la vez las demostraciones y sus explicaciones en varios estilos de demostración y formatos de enunciados. Inicialmente, se incluyen los estilos "inglés” (English), “demostración” (Proof) y Dag[7] y los formatos preferentes de enunciados “inglés” (English), "KIF[8]" y “Raw[9]”. También se tiene en cuenta que algunas aplicaciones puedan implementar sus propias visualizaciones usando el IW API. El navegador de IW utiliza la metáfora de la lente u objetivo para rendir un número fijo de niveles de pasos de inferencia (InferenceSteps) dependiendo de la magnitud de la lente. El navegador del prototipo permite que un usuario vea simultáneamente hasta cinco niveles de pasos de inferencia (InferenceSteps) junto con sus conclusiones y antecedentes.
La figura 5 muestra la pantalla del navegador que presenta dos niveles de InferenceSteps para una demostración de un caso de uso del vino. Antes de mostrar la vista, el programa ha preguntado qué vino servir en un curso de mariscos. La figura 5 muestra un fragmento de la demostración que concluye que ese Nuevo-curso (New-course), que es el curso de comida seleccionado, requiere una bebida que tenga un color blanco puesto que es un curso de mariscos. El formato de los enunciados es inglés y la magnitud de la lente es dos, así el navegador muestra los pasos de la inferencia (InferenceSteps) usados para derivar la conclusión del fragmento de la demostración incluyendo sus antecedentes y las derivaciones del antecedente. En cuanto a formatos preferentes de los enunciados, el navegador soporta algunas traducciones restringidas entre enunciados que se pueden solicitar por el usuario. Por ejemplo, el formato "Raw" indica que el usuario desea ver las conclusiones del sistema de nodos (NodeSet) según estaban originalmente. Sin embargo, si el usuario selecciona "KIF", entonces si las conclusiones del sistema de nodos (NodeSet) no están ya en KIF, y el navegador tiene un traductor del lenguaje original a KIF, entonces el navegador traduce y presenta los enunciados en KIF. Si no, presenta el enunciado en su lenguaje original. El mismo método se utiliza para traducir otros formatos, por ejemplo en inglés.
Figura 5 – Una pantalla del navegador de IW
Una de las claves de la presentación de justificaciones es que parte las demostraciones en fragmentos separables. Puesto que se muestran los fragmentos, el soporte automático para el seguimiento de la pregunta es una función crítica del navegador de IW. Cada elemento en la lente de la presentación o vista puede accionar una acción del navegador. La selección de un antecedente refocaliza la lente hacia el paso de la inferencia (InferenceStep) del antecedente. Para otros elementos de la lente, hay acciones asociadas que presentan la meta información de IW Base. La selección del recuadro del motor de inferencia presenta los detalles sobre el motor de inferencia usado para derivar el teorema actual. La selección del recuadro de la regla de inferencia presenta una descripción de la regla. La selección del icono de la fuente al lado de enunciados asociados a documentos fuente presenta los detalles de las fuentes donde se ha definido el axioma. En la figura 5, seleccionando el recuadro "Generalized Modus Ponens” la regla de inferencia, presentará la información sobre la regla generalizada de Modus Ponens en JTP como aparece en la figura 3.
Explanation Dialogue Component La Web Inferencial incluye un nuevo componente de diálogo de explicaciones diseñado después de analizar comportamientos de uso. La figura 6 muestra el explainer de IW que explica porqué WINE9 tiene color blanco. La idea es presentar un formato simple que sea una abstracción típica de la información que apoya una conclusión. La implementación actual proporciona una presentación de la pregunta y de la respuesta, los hechos de base sobre los que se fundamenta la respuesta, y una abstracción de la meta información sobre esos hechos. Hay también una opción de la acción de seguimiento que permite que los usuarios naveguen por la demostración o la explicación, obtengan las suposiciones que fueron utilizadas, consigan más meta información sobre las fuentes, tengan una entrada al sistema, etc. Toda la información presentada en cualesquiera de las pantallas es de última hornada, de manera que si alguien clica cualquier elemento de la explicación, pueda obtener información sobre ese elemento incluyendo su descripción y meta información. Se espera que este interfaz sea el interfaz con el cual el usuario medio de la Web Inferencial interactúe.
Figura 6 – Una pantalla del Explainer
[1] Cada Binding de un InferenceStep es un mapeado que va de una variable a un término especificando las sustituciones que se han ido haciendo en las premisas antes de la aplicación de las reglas de los steps. Un InferenceStep puede tener ningún, uno o varios bindings y cada binding es de tipo VariableBinding. Por ejemplo, las substituciones pueden ser requeridas para unificar términos en las premisas a fin de conseguir la solución [2] Se dice que un InferenceStep está bien formado si: 1. Su conclusión del NodeSet es una instancia del esquema de conclusión especificado por su regla; 2. Las expresiones resultantes de aplicar su binding a sus esquemas de premisa son instancias de sus esquemas de premisas de regla; 3. Tiene el mismo número de premisas que sus esquemas de premisas de regla [3] LanguageAxiomSet es una subclase de Ontology [4] Una API (del ingles Application Programming Interface - Interface de Programación de Aplicaciones) es un conjunto de especificaciones de comunicación entre componentes software. Representa un método para conseguir abstracción en la programación, generalmente (aunque no necesariamente) entre los niveles o capas inferiores y los superiores del software. Uno de los principales propósitos de una API consiste en proporcionar un conjunto de funciones de uso general, por ejemplo, para dibujar ventanas o iconos en la pantalla. De esta forma, los programadores se benefician de las ventajas de la API haciendo uso de su funcionalidad, evitándose el trabajo de programar todo desde el principio. Las APIs asimismo son abstractas: el software que proporciona una cierta API generalmente es llamado la implementación de esa API. [5] SOAP (siglas de Simple Object Access Protocol) es un protocolo estándar creado por el W3C que define cómo dos objetos en diferentes procesos pueden comunicarse por medio de intercambio de datos XML. SOAP es uno de los protocolos utilizados en los servicios Web. [6] El Concurrent Version System (CVS), implementa un sistema de control de versiones : mantiene el registro de todo el trabajo y los cambios en la implementación de un proyecto (de programa) y permite que distintos desarrolladores (potencialmente situados a gran distancia ) colaboren. CVS se ha hecho popular en el mundo del software libre. [7] Abreviatura de Directed Acyclic Graph. Es un término técnico usado en jerarquías. Viene a decir que si has recorrido desde el primer nodo en una jerarquía hasta el último, nunca deberías ver el mismo nodo dos veces. Una colección de nodos (puntos o cajas) y filos (lineas del conector) que se usan en informática para describir una secuencia de eventos computacionales; un grafo dirigido va en una dirección particular; un grafo acíclico dirigido no puede pasar dos veces por él mismo [8] Knowledge Interchange Format. Formato de Intercambio de Conocimiento [9] Los datos en "Raw" son una colección de elementos sin información adicional sobre la presentación. En la cocina serían un sistema o set de ingredientes e irían hasta el procesador para seleccionar los elementos apropiados, arreglarlos para su presentación y añadirles información sobre lo que se requiere en la presentación.
|
|
|
En nuestra opinión, la Web Semántica y la IW son, en si mismas, una solución pensada desde una concepción documentalista de la web. Por lo que, pensamos, que cualquier aplicación que surja desde estos campos, es una aplicación utilizable en nuestra área de trabajo y estudio.
Tal y como presentamos la idea en el párrafo anterior, podría parecer algo ambigua, pero si consideramos que la IW lo que trata es de hacer comprensibles los procesos de las aplicaciones y servicios de la Web Semántica a los usuarios (ya sean máquinas o seres humanos), así como ofrecer respuestas a las cuestiones que estos le planteen, entonces podemos decir que la IW trabaja tratando información, previamente catalogada y “semantizada” mediante lenguajes ontológicos basados en metadatos y ofreciendo esta información de forma utilizable para cada usuario. De esta forma, cualquier forma de trabajo sobre información, aplicada a la Documentación en un entorno web puede beneficiarse de las herramientas de la IW.
Para ver esto de forma más clara vamos a imaginar un ejemplo de aplicación de la IW en nuestro entorno. Supongamos que existe una Red Bibliotecas Digitales, cuyos entornos web utilizan estándares de Web Semántica y emplean agentes para interactuar dentro de dicha red. Además estas Bibliotecas Digitales tienen sus documentos en ficheros descritos por metadatos. En este entorno, es necesario un marco de trabajo (framework) como es la IW, que permita a estos agentes y a los usuarios de la red interactuar y trabajar con los procesos de los distintos nodos de la Red.
Por ejemplo, un usuario de esta red lanza una consulta, imaginemos que necesita un documento, a texto completo, del autor de “La vida maravillosa” del que no conoce el nombre, escrito en un determinado año y que en el titulo aparecen ciertas palabras. Además tiene configurado su agente de información, para que los textos completos se los muestre con una presentación determinada (títulos de capitulo, con un formato, texto de contenido con otro, notas a pie de determinada forma, etc) y en un fichero pdf.
En este ejemplo es la IW la que trabaja en la red con los diferentes agentes, cuando la encuentra extrae la información y la hace comprensible a el agente del usuario para que reconozca los distintos componentes del texto y los combine a gusto del mismo.
Este simple consulta nos da una idea de todas las aplicaciones que nos ofrece el que las maquinas puedan entender la información de la web y trabajar con ella trasformándola según nuestras necesidades.
|
|
| 4. CONCLUSIONES | |
|
Hablando de la Web Semántica y la IW y su futuro hay autores que la muestran como algo inevitable e irremediable y, por el contrario autores que la tiran por tierra y la tratan como un proyecto sin futuro. Para nosotros, sin embargo, ni todo es de color de rosa ni se trata de un proyecto vacío. La Web Semántica y la IW, como framework, son un modelo utópico si lo que queremos es que toda la web se adapte y se cree según este modelo, no vemos factible que todos los desarrolladores tengan el interés necesario y el tiempo como para crear sitios y adaptar los ya creados a estas tecnologías. No olvidar que gran parte de la web esta creada por pequeños desarrolladores. Pero lo que si creemos es que en muchos círculos o áreas, como podrían ser: la Documentación, la Investigación científica, Industria, Servicios web (comercio electrónico, publicidad, etc), el futuro de este proyecto es muy alentador ya que se adapta perfectamente a sus necesidades. También, un argumento que apoya esta última idea es el rápido y fuerte crecimiento en investigación y en apoyo, también, por parte de la empresa privada dentro de este área, que se a producido desde finales de la década de los noventa hasta la actualidad.
|
|
| 5. BIBLIOGRAFÍA | |
Webs
Artículos
Publicaciones de Conferencias
|
|