LA WEB SEMÁNTICA
Vanessa Armengol
1. La Web Semántica
1.1. Historia
1.2. ¿Qué es?
1.3. ¿Para qué sirve?
1.4. ¿Cómo funciona?
2. Elementos básicos de la Web Semántica
2.1. XML
2.2. RDF
2.3. OIL
2.4. DAML y DAML+OIL
2.5. PICS
2.6. Ontologías
2.7. Agentes
3. La recuperación de información en la Web Semántica
4. Ejemplos de Web Semántica
5. Aplicaciones
5.1. Aplicaciones en la recuperación de información
5.2. Otras aplicaciones
6. La Web Semántica hoy
7. Perspectivas de futuro
8. Bibliografía
1. La Web Semántica
1.1. Historia
La aparición de la WWW se puede situar en 1989 [Abrams 1998, Connolly 2000], cuando Tim Berners-Lee presentó su proyecto de “World Wide Web” [Berners-Lee 1989] en el CERN (Suiza), con las características esenciales que perduran en nuestros días. El propio Berners-Lee completó en 1990 el primer servidor web y el primer cliente, y un año más tarde publicó el primer borrador de las especificaciones de HTML y HTTP.
El lanzamiento en 1993 de Mosaic, el primer navegador de dominio público, compatible con Unix, Windows, y Macintosh, por el National Center for Supercomputing Applications (NCSA), marca el momento en que la WWW se da a conocer al mundo, extendiéndose primero en universidades y laboratorios, y en cuestión de meses al público en general, iniciando el que sería su vertiginoso crecimiento. Los primeros usuarios acogieron con entusiasmo la facilidad con que se podían integrar texto y gráficos y saltar de un punto a otro del mundo en una misma interfaz, y la extrema sencillez para contribuir contenidos a una web mundial.
Por estas mismas fechas se define la interfaz CGI para la generación dinámica de páginas web, con lo que se consigue ofrecer información actualizada en tiempo real, enlazar con bases de datos, o tener en cuenta entradas del usuario, y más aún, servir como punto de acceso y plataforma para la ejecución de aplicaciones distribuidas.
En 1994 miembros del equipo que creó Mosaic desarrollan Netscape, un navegador con sensibles mejoras que contribuye a impulsar la propagación de la web. Este mismo año se celebra el primer congreso internacional de la WWW, y unos meses más tarde se constituye el consorcio W3C, que desde entonces y presidido por Tim Berners-Lee, se ha hecho cargo de estandarizar las principales tecnologías web.
En 1995 Sun lanza oficialmente la primera versión del
lenguaje Java, y un año más tarde Netscape presenta JavaScript.
Estos lenguajes y otros posteriores permiten que las propias páginas
web contengan programas enteros, dando opción a una mayor autonomía
respecto del servidor, mayor eficiencia, capacidad dinámica y capacidad
de interacción.
El problema de Internet actualmente es que sólo se trata de una enorme
base de datos que contiene los documentos, artículos o archivos multimedia,
inconexos de los usuarios de medio mundo. Los actuales documentos de HTML a
pesar de poseer cierta cantidad de metadatos que permite su indexación
en buscadores, esta sólo se refiere al formato del documento en general
y no a cada uno de sus componentes.
Los agentes de búsqueda no se diseñan para “comprender”
la información que reside en la web. Por este motivo, cuando introducimos
unas palabras en un buscador, éste lo interpreta como una “simple
cadena de caracteres” sin tener en cuenta su contenido semántico,
produciéndose mucho ruido en los resultados obtenidos. Esto ocurre, porque
la red actual está pensada para ser leída por los humanos y no
por las máquinas, que no pueden entenderla.
Para ello, Berners-Lee, junto con otros investigadores, está dando forma
a la Web Semántica, entendida como “una web donde los ordenadores
no sólo serán capaces de presentar toda la información
contenida en la web sino que, además, podrán “entenderla”
y gestionarla de forma “inteligente” o lógica” (Tim
Berners-Lee, 2001).
La Web Semántica se describe como una extensión de la Web actual
en la que la información podrá ser procesada automáticamente
por los ordenadores, posibilitando que éstos puedan llevar a cabo tareas
más complejas para los usuarios.
El funcionamiento básico de la Web Semántica se basará
en la compatibilidad de todos los datos. Se intentará convertir la información
en conocimiento, referenciando datos dentro de las páginas web con metadatos
en un esquema común consensuado sobre algún dominio. Los metadatos,
además de especificar el esquema de datos, podrán tener información
adicional de cómo hacer deducciones de ellos.
Con esto, se mejorarán las búsquedas de información y las
aplicaciones de comercio electrónico, ya que las anotaciones de información
seguirán un esquema común, y los buscadores web compartirán
con las anotaciones web los mismos esquemas.
Los agentes web encontrarán la información de forma precisa, además
podrán realizar inferencias automáticamente buscando información
relacionada con la que se encuentra situada en las páginas, y con los
requerimientos de la consulta indicada por el usuario.
1.2. ¿Qué es?
La Web Semántica es una Web extendida, dotada de mayor significado en la que cualquier usuario en Internet podrá encontrar respuestas a sus preguntas de forma más rápida y sencilla gracias a una información mejor definida. Al dotar a la Web de más significado y, por lo tanto, de más semántica, se pueden obtener soluciones a problemas habituales en la búsqueda de información gracias a la utilización de una infraestructura común, mediante la cual, es posible compartir, procesar y transferir información de forma sencilla. Esta Web extendida y basada en el significado, se apoya en lenguajes universales que resuelven los problemas ocasionados por una Web carente de semántica en la que, en ocasiones, el acceso a la información se convierte en una tarea difícil y frustrante.
1.3. ¿Para qué sirve?
La Web ha cambiado profundamente la forma en la que nos comunicamos, hacemos
negocios y realizamos nuestro trabajo. La comunicación prácticamente
con todo el mundo en cualquier momento y a bajo coste es posible hoy en día.
Podemos realizar transacciones económicas a través de Internet.
Tenemos acceso a millones de recursos, independientemente de nuestra situación
geográfica e idioma. Todos estos factores han contribuido al éxito
de la Web. Sin embargo, al mismo tiempo, estos factores que han propiciado el
éxito de la Web, también han originado sus principales problemas:
sobrecarga de información y heterogeneidad de fuentes de información
con el consiguiente problema de interoperabilidad.
La Web Semántica ayuda a resolver estos dos importantes problemas permitiendo
a los usuarios delegar tareas en software. Gracias a la semántica en
la Web, el software es capaz de procesar su contenido, razonar con este, combinarlo
y realizar deducciones lógicas para resolver problemas cotidianos automáticamente.
1.4. ¿Cómo funciona?
Supongamos que la Web tiene la capacidad de construir una base de conocimiento
sobre las preferencias de los usuarios y que, a través de una combinación
entre su capacidad de conocimiento y la información disponible en Internet,
sea capaz de atender de forma exacta las demandas de información por
parte de los usuarios en relación, por ejemplo, a reserva de hoteles,
vuelos, médicos, libros, etc.
Si esto ocurriese así en la vida real, el usuario, en su intento, por
ejemplo, por encontrar todos los vuelos a Praga para mañana por la mañana,
obtendría unos resultados exactos sobre su búsqueda. Sin embargo
la realidad es otra.
La figura 1 muestra los resultados inexactos que se obtendrían con el
uso de cualquier buscador actual, el cual ofrecería información
variada sobre Praga pero que no tiene nada que ver con lo que realmente el usuario
buscaba.
El paso siguiente por parte del usuario es realizar una búsqueda manual
entre esas opciones que aparecen, con la consiguiente dificultad y pérdida
de tiempo. Con la incorporación de semántica a la Web los resultados
de la búsqueda serían exactos.
La figura 2 muestra los resultados obtenidos a través de un buscador
semántico. Estos resultados ofrecen al usuario la información
exacta que estaba buscando. La ubicación geográfica desde la que
el usuario envía su pregunta es detectada de forma automática
sin necesidad de especificar el punto de partida, elementos de la oración
como "mañana" adquirirían significado, convirtiéndose
en un día concreto calculado en función de un "hoy".
Algo semejante ocurriría con el segundo "mañana", que
sería interpretado como un momento determinado del día. Todo ello
a través de una Web en la que los datos pasan a ser información
llena de significado.
El resultado final sería la obtención de forma rápida y
sencilla de todos los vuelos a Praga para mañana por la mañana.
Buscador Actual
Resultados de la búsqueda:
Toda la magia de Budapest y Praga
... Suplementos Gran Premio Fórmula 1 en Budapest para las salidas del
... con Ferias y/o Congresos en Praga del 9 ... Más información
de los vuelos ...
LA VANGUARDIA DIGITAL - Praga, testigo de la historia europea
... Para emergencias el teléfono de la policía es el 150, el de
las ambulancias el ... 46) y Praga tres días por semana. Los vuelos salen
de Madrid (Tel ...
Foros sobre Europa República Checa Praga inkietante
... solo decirte que me llamó la atención tu alias (aunque no
me llamo Raula) y que me voy mañana mismo para Praga ... buscador de
vuelos ...
ofertas de espectáculos, viajes y hoteles al mejor precio
... autoridades que tienen tres copas gigantes para entregar a ... mañana
creo que cogeremos el bus mañana ... En Atrápalo puedes también
reservar vuelos ...
Figura 1 - Resultados obtenidos con un buscador normal
Buscador Semántico
Resultados de la búsqueda:
viajaconnosotros.com - viajes a Praga
... todos los vuelos a Praga desde tu ciudad que saldrán mañana
por la mañana, ordenados según su hora de salida ...
viajes a Praga - vuelos disponibles
... lista de vuelos. Horarios de salida y llegada ...
Ofertas especiales - vuelos a Praga
... ofertas especiales de vuelos a Praga ...
Figura 2 - Resultados obtenidos con un buscador semántico
La forma en la que se procesará esta información no sólo
será en términos de entrada y salida de parámetros sino
en términos de su SEMÁNTICA. La Web Semántica como infraestructura
basada en metadatos aporta un camino para razonar en la Web, extendiendo así
sus capacidades.
No se trata de una inteligencia artificial mágica que permita a los ordenadores
entender las palabras de los usuarios, es sólo la habilidad de una máquina
para resolver problemas bien definidos, a través de operaciones bien
definidas que se llevarán a cabo sobre datos existentes bien definidos.
Para obtener esa adecuada definición de los datos, la Web Semántica
utiliza RDF y OWL, dos estándares que ayudan a convertir la Web en una
infraestructura global en la que es posible compartir, y reutilizar datos y
documentos entre diferentes tipos de usuarios.
· RDF proporciona información descriptiva simple sobre los recursos
que se encuentran en la Web y que se utiliza, por ejemplo, en catálogos
de libros, directorios, colecciones personales de música, fotos, eventos,
etc.
· OWL es un mecanismo para desarrollar temas o vocabularios específicos en los que asociar esos recursos. Lo que hace OWL es proporcionar un lenguaje para definir ontologías estructuradas que pueden ser utilizadas a través de diferentes sistemas. Las ontologías, que se encargan de definir los términos utilizados para describir y representar un área de conocimiento, son utilizadas por los usuarios, las bases de datos y las aplicaciones que necesitan compartir información específica, es decir, en un campo determinado como puede ser el de las finanzas, medicina, deporte, etc. Las ontologías incluyen definiciones de conceptos básicos en un campo determinado y la relación entre ellos.
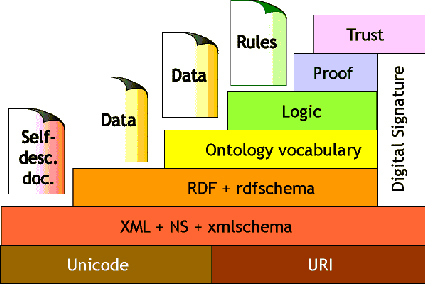
2. Elementos básicos de la Web Semántica
Las diferentes Capas
A continuación se explica brevemente las diferentes capas que componen
la Web Semántica:
· Unicode
Unicode es una codificación del texto que permite utilizar los símbolos
de diferentes idiomas sin observar caracteres extraños. Esto permite
expresar información en la Web Semántica en cualquier idioma.
· URI
URI es el acrónimo de Uniform Resource Identifier, o en castellano, Identificador
Uniforme de Recursos. Es un poco confusa la diferencia entre URI y URL, por
lo que vamos a decir que un URL es un recurso que puede ser accedido vía
Internet.
· XML + NS + xmlschema
Tal vez la capa más técnica de la Web Semántica. En esta
capa se agrupan las diferentes tecnologías que hacen posible que los
agentes puedan entenderse entre ellos.
· RDF + rdfschema
Directamente basada y apoyada en la capa anterior, esta capa define el lenguaje
universal con el cual podemos expresar diferentes ideas en la Web Semántica.
· Lenguaje de Ontologías
Los lenguajes de ontologías nos permiten extender la funcionalidad de
la Web Semántica, agregando nuevas clases y propiedades para describir
los recursos.
· Lógica
· Prueba
· Confianza
· Firma Digital
2.1. XML
XML (eXtensive Markup Language), permite la codificación para la distribución
de documentos complejos por Internet.
Vamos a dar unos datos previos que hará más fácil entender
porque se elige este formato.
SGML (Standard Generalized Markup Language) es una norma que pretende establecer
una manera genérica de especificar, definir documentos, la cual permitiese
a su vez usar formatos de mayor flexibilidad y portabilidad. Con lo cual reunía
tres condiciones básicas:
1. Formal: pues permite establecer la validez de los documentos
2. Estructurado: para que fuese capaz de manejar documentos complejos
3. Ampliable: para facilitar la gestión de grandes depósitos de
información
XML es un subconjunto de SGML, y define un formato de texto diseñado
para la transmisión de datos estructurados. Al ser un subconjunto de
SGML mantiene sus características de validación, estructurado
y especialmente facilita la extensibilidad, porque es un metalenguaje que permite
describir lenguajes de marcas, tanto la definición de etiquetas como
la relación estructural que existe entre ellas.
Un ejemplo de como funciona XML sería algo así:
<agenda>
<persona>
<nombre>Kike</nombre>
<telefono>638002993</telefono>
<comentario>Es
un bombon</comentario>
</persona>
<persona>
<nombre>Maria</nombre>
<telefono>956-78.90.12</telefono>
<telefono>652135792</telefono>
</persona>
</agenda>
2.2. RDF
RDF son las siglas definen Resource Description Framework (algo así como
marco de descripción de recursos) Como su nombre indica el área
en la que está enmarcado es la descripción de recursos de la red,
entendiendo por recurso todo lo que nos dé de sí la imaginación
en tanto que a definir cualquier cosa, páginas, personas, dispositivos...
RDF permite que las condiciones que se quieren "preguntar" sobre un
recurso sean definidas como un conjunto de propiedades que componen el esquema.
RDF ofrece una estructura semántica inambigua (por el uso de los URI,
Uniform Resource Identifier) que permite codificación, intercambio y
procesamiento automático de los metadatos normalizados.
RDF proporciona también reglas para facilitar técnicamente la
manera de explicar conceptos de modo que los ordenadores puedan procesarlo rápidamente
y proporciona un medio que posibilita la edición de vocabularios con
propiedades definidas para la descripción de los recursos de una comunidad.
RDF usa la sintaxis del lenguaje XML para el intercambio y procesamiento de
metadatos, las condiciones se recogen en los rdf: Descripcion de los elementos
XML.
2.3. OIL
OIL (Lenguaje de Intercambio de Ontologías = Ontology
Interchange Language) es un lenguaje estándar propuesto por el “Proyecto
OnToKnowledge” (www.ontoknowledge.org).
El OIL fusiona tres paradigmas:
1. modelo de datos basado en frames o marcos con
2. semántica basada en lógica de descripción y
3. sintaxis basada en normas de la web como el XML y el Esquema RDF.
El OIL se ha aplicado con éxito en muchas áreas como la gestión
del conocimiento o el comercio electrónico.
2.4. DAML y DAML+OIL
El DAML (Darpa Agent Markup Language) es un lenguaje creado
por DARPA como un lenguaje de inferencia y ontología basado en RDF. DAML
va un paso por delante del Esquema RDF al proporcionarnos propiedades y clases
con más profundidad. DAML permite ser más expresivo que con el
Esquema RDF y nos devuelve a lo que era el debate sobre al Web Semántica
al proporcionarnos términos simples para crear inferencias.
El DAML nos da un método para expresar cosas tales como propiedades únicas
y no ambiguas, listas, restricciones, cardinalidades, listas de paridad disjuntas
y tipos de datos, etc.
A continuación podemos ver un ejemplo de lo anterior:
Una construcción de DAML que podríamos ver es la propiedad daml:inverseOf.
El eso de esta propiedad permite expresar que una propiedad es inversa de otra.
Los valores rdfs:range y rdfs:domain, del daml:inverseOf es rdf:Property. Aquí
tenemos un ejemplo de daml:inverseOf
:hasName daml:inverseOf :isNameOf .
:Pepe :hasName "Pepe” .
"Pepe" :isNameOf :Pepe.
La segunda construcción útil de DAML que podríamos ver
es la clase daml:UnambiguousProperty.
Decir que una propiedad es un daml:UnambiguousProperty significa que si el objeto
de la propiedad es el mismo, entonces los sujetos son equivalentes:
foaf:mbox rdf:type daml:UnambiguousProperty .
:x foaf:mbox .
:y foaf:mbox .
implica que:
:x daml:equivalentTo :y .
Recientemente, el “Comité Conjunto Especial de Estados Unidos y
la Unión Europea de Lenguajes Marcado de Agentes” (Joint US/EU
ad hoc Agent Markup Language Committee) ha publicado el DAML+OIL, como el lenguaje
estándar de representación de ontologías en Marzo de 2001
(www.daml.org/2001/03/daml+oil-index). Este lenguaje va un paso por delante
del DAML y fusiona características de OIL y DAML.
2.5. PICS
Los PICS (Platform for the Internet Content Selection), nos indican lo adecuado
o conveniente de determinados ficheros de datos según la comunidad en
la que se encuentre el usuario. Es una infraestructura para asociar las etiquetas
con los contenidos de Internet. Aunque en un principio estaba destinado al control
del acceso de los niños a Internet, su uso se puede extender a otras
etiquetas que incluyan privacidad, licencias, etc. PICS es una plataforma sobre
la cual se han construido otros servicios de clasificación que no sólo
define una manera de construir etiquetas sino que es un mecanismo para realizar
las valoraciones. Este mecanismo esta formado, al menos por lo siguiente:
· Las etiquetas, que son los metadatos que indican la valoración
de un documento
· Los servicios de valoración, es decir, las organizaciones, grupos
o personas que realizan una valoración
· Los perfiles, que son las reglas que da el usuario para definir el
filtro para evitar recibir documentos no deseados.
Para que el filtrado de documentos no deseados se lleve a cabo, también
es necesario un software cliente y otro servidor que tengan implementado el
sistema de valoración. Estas funciones se pueden realizar por separado,
lo cual permite que por un lado los desarrolladores de software puedan realizar
una aplicación informática sin suministrar un sistema de valoración
mientras que por otro una organización puede crear sistemas de valoración
sin tener que desarrollar el software.
2.6. Ontologías
Las ontologías son colecciones de enunciados redactados en un lenguaje, como el RDF, que define las relaciones entre conceptos y especifica reglas lógicas para razonar con ellos. Los ordenadores "comprenderán" el significado de los datos semánticos de una página de la red siguiendo vínculos con ontologías especificadas.
2.7. Agentes
El concepto de tecnología de agentes está aún en desarrollo,
pero una definición que podemos manejar de agente es la siguiente: un
agente es una entidad de software que funciona continua y autónomamente
en un medio particular a menudo habitado por otros agentes y procesos, sin requerir
de guía constante o intervención humana. En otras palabras, un
agente es un asistente personal que está dentro de la computadora y que
cumple varios roles en representación de una función específica
o de un usuario.
En la web semántica serán los encargados de realizar la búsqueda
de servicios, para ello, la semántica facultará a los agentes
para describir unos a otros la función exacta que realizan, y qué
datos han de recibir para ello.
3. La recuperación de información en la Web Semántica
Los actuales buscadores de Internet, como google se basan en un sistema en el
que los usuarios meten manualmente los enlaces y al hacer una búsqueda
se aplica un algoritmo de emparejamiento de patrones, que tiene en cuenta el
número de veces que se hace referencia a cada URL candidata a ser resultado
de búsqueda.
Si bien hemos aprendido a convivir con este sistema de búsqueda, la única
información que recuperamos con él son conceptos descontextualizados,
es decir, si en un buscador ponemos la palabra "flor" recuperaremos
una editorial que se llame flor, una página web para expresar sentimientos
en Internet y, si tenemos suerte alguna página especializada en margaritas.
La web semántica nos permitirá hacer búsquedas precisas
del tipo quiero el viaje más barato que hay entre Madrid y Barcelona,
teniendo en cuenta que me gusta ir en ventanilla y en no fumadores.
En el estado actual de Internet esto es ahora posible gracias a los sistemas
multiagente. Donde un agente es una entidad de software que funciona continua
y autónomamente en un medio particular a menudo habitado por otros agentes
y procesos, sin requerir de guía constante o intervención humana.
También debe poseer ciertas habilidades sociales, reactividad ante el
mundo que le rodea y comportamiento basado en deseos que pertenecen a cada agente
en particular. Los sistemas multiagentes se han propuesto como la mejor herramienta
para realizar aprendizaje automático en Internet. Mediante esta herramienta
es posible hacer recomendaciones acertadas del tipo "pincha en este sitio
web, pues me parece que te interesa", "esta persona tiene intereses
muy similares a los tuyos, te interesaría contactar con ella" y
esto lo hará software puro y duro, sin más intervención
humana que la de la propia acción del usuario y acertarán. También
será posible clasificar automáticamente sitios ó documentos
de una manera acertada y un montón de más cosas que ni siquiera
nos imaginamos.
El problema con el que ahora se topa la tecnología de sistemas multiagente
es la volatilidad y desestructuración de la información base para
realizar las inferencias. Volviendo al ejemplo del sistema multiagente para
encontrar el viaje de tus sueños el único lugar desde el que puede
recuperar la información son páginas html en forma de tablas,
éstas páginas pueden cambiar su estructura cada mes, lo que requiere
cambios de programación. Esto no es un problema si la información
está almacenada y puede ser consultada desde bases de datos y/o ficheros
xml/rdf.
Hoy en día podemos ver cómo se popularizan foros al estilo de
slashdot que dejan un fichero rdf (por ejemplo http://slashdot.rdf), dónde
quedan las noticias de manera estructurada. La idea es que éste u otros
métodos de compartir la información dinámica se popularice.
Mientras tanto esta tecnología quedará res
tringida a poderosas bases de datos centralizadas como por ejemplo
las de Amazon, que hagan recomendaciones de compra en base a lo que ya se ha
comprado.
4. Ejemplos de Web Semántica
Dos de los ejemplos más conocidos de aplicación de Web Semántica
son RSS y FOAF.
· RSS es un vocabulario RDF basado en XML que permite
la catalogación de información (noticias y eventos) de tal manera
que sea posible encontrar información precisa adaptada a las preferencias
de los usuarios. Los archivos RSS contienen metadatos sobre fuentes de información
especificadas por los usuarios cuya función principal es avisar a los
usuarios de que los recursos que ellos han seleccionado para formar parte de
esa RSS han cambiado sin necesidad de comprobar directamente la página,
es decir, notifican de forma automática cualquier cambio que se realice
en esos recursos de interés seleccionados. Un ejemplo de la aplicación
de RSS se puede encontrar en las Noticias de la Oficina Española del
W3C como canal RSS (http://www.w3c.es/noticias.rss).
· FOAF es un proyecto de Web Semántica, que permite
crear páginas Web para describir personas, vínculos entre ellos,
y cosas que hacen y crean. Se trata de un vocabulario RDF, que permite tener
disponible información personal de forma sencilla y simplificada para
que pueda ser procesada, compartida y reutilizada. Dentro de FOAF podemos destacar
FOAF-a-Matic (http://www.ldodds.com/foaf/foaf-a-matic.es.html), que se trata
de una aplicación Javascript que permite crear una descripción
FOAF de uno mismo. Con esta descripción, los datos personales serán
compartidos en la Web pasando a formar parte de un motor de búsqueda
donde será posible descubrir información a cerca de una persona
en concreto y de las comunidades de las que es miembro de una forma sencilla
y rápida. FOAFNAUT (http://www.foafnaut.org/), por su lado, se utiliza
para mostrar relaciones de estructuras FOAF con SVG.
Los buscadores semánticos son un ejemplo más de aplicaciones basadas
en Web Semántica. El objetivo es satisfacer las expectativas de búsqueda
de usuarios que requieren respuestas precisas. Otros ejemplos de aplicaciones
basadas en Web Semántica pueden encontrarse en:
SWAD-Europe: Aplicaciones de Web Semántica - análisis y selección
(http://www.w3.org/2001/sw/Europe/reports/open_demonstrators/hp-applications-survey).
5. Aplicaciones
5.1. Aplicaciones en la recuperación de información
Greg Newby hace un análisis sobre los hechos que deben
ser tenidos en cuenta para el desarrollo de la Web Semántica. Este análisis
se estructura sobre los conceptos de “espacio de información”,
que se define como el conjunto de conceptos y relaciones entre los mismos soportadas
por un sistema de información, y su contrapuesto “espacio cognitivo”
que es el conjunto de conceptos y relaciones entre los conceptos que conoce
un humano.
Se considera que un objetivo a largo plazo para los Sistemas de Recuperación
de la Información (SRI), es actuar como extensiones de la memoria humana.
Para conseguir este objetivo los “espacios de información”
de los SRIs deberán parecerse cada vez más a los “espacios
cognitivos” humanos. La WS ayudará a dar pasos en esta dirección.
Para que la comunicación tenga éxito, tanto entre máquinas
como entre humanos, debe existir un mapa conceptual común. Esto es lo
que tratan de solucionar las ontologías y los traductores de ontologías
o las herramientas de integración de ontologías. Los métodos
de búsqueda actuales tratan de establecer un vínculo entre las
palabras de una consulta y las palabras de un documento. Lo que se pretende
lograr es que los nuevos sistemas enlacen una necesidad de información
con el contenido de un documento.
Para ello hay esencialmente tres técnicas relacionadas con la WS:
- Técnicas de mapeo directo.
- Técnicas basadas en reglas.
- Técnicas derivadas del contexto.
Los SRI se basan para efectuar sus búsquedas, en una combinación
de factores basados en cadenas de caracteres que, como sabemos, producen muchos
problemas. Pero son técnicas que han demostrado cierta eficacia y no
sería bueno descartarlas. Seguramente deberán ser combinadas con
las nuevas técnicas de recuperación para, por ejemplo, ordenar
los resultados.
Todos sabemos cómo funciona una búsqueda tradicional/actual. Tecleamos
palabras relacionadas con nuestra necesidad de información y obtenemos
muchos documentos de los cuáles sólo algunos nos interesan. Nuestra
satisfacción en la búsqueda aumentaría considerablemente
si pudiésemos añadir con garantías criterios de búsqueda
tales como: tipo de documento, tipo de autor del documento, tema principal,
etc. Por ejemplo podríamos buscar páginas sobre comida para perros,
pero que estuviesen elaboradas por un veterinario. Incluso podríamos
pedirle que nos devolviese aquellas que, aunque no fuesen obra de veterinarios,
estuviesen enlazadas desde páginas de asociaciones de veterinarios.
Para evitar los problemas de ambigüedad del lenguaje en la recuperación
de información se necesita una rica estructura de marcado de los documentos.
Ésta se irá creando en la medida que:
- Todos los usuarios podrán ser autores.
- Podrán crear nuevos conceptos.
- Podrán crear nuevas relaciones entre los conceptos que ya existan.
- Los usuarios son “propietarios” de la información que han
creado.
- Los usuarios son conceptos.
- Los agentes son usuarios.
Aunque la recuperación inteligente de información aún no
puede ser considerada como un hecho, ya existen prototipos que se basan en la
semántica, por ejemplo BUSTER, desarrollado por la Universidad de Bremen.
Está formado por dos partes:
- BUSTER/Q: una herramienta para la recuperación inteligente
de información.
- BUSTER/SI: una herramienta para la integración semántica de
fuentes de datos heterogéneas. Tienen disponible una demo en su web (http://www.semantic-translation.com/).
Por último cabe destacar UIMA, una iniciativa de IBM que, dicen algunos
autores, desbancará al mismísimo Google. UIMA (Unstructured Informartion
Management Arquitectura) es una estructura de recuperación de datos basada
en XML. Se fundamenta en hipótesis de combinación y en inteligencia
artificial sintáctica, además de incluir elementos de procesamiento
de lenguaje natural.
5.2. Otras aplicaciones
Además de los motores de búsqueda, existen otras
funciones o tareas que conviene que sean realizadas por agentes automáticos
los cuales pueden mejorar su rendimiento a través de la Web Semántica.
Conviene añadir que, todos estos usos, son en realidad derivaciones de
la Recuperación de Información:
- Comercio electrónico: el comercio electrónico
ha adquirido una gran relevancia en la actualidad. De hecho tres de cada cinco
empresas utilizan en alguna medida el comercio electrónico, además
hay una clara tendencia al incremento en el uso del comercio electrónico.
Por este motivo el uso de las tecnologías relacionadas con la red semántica
se convierte en un tema fundamental de interés.
La tecnología ontológica se convierte en una tecnología
prometedora para el comercio electrónico desde donde se proporciona un
marco para la integración de información, una estructura conceptual
y se permite la integración adicional con búsqueda y recuperación
basadas en el conocimiento de la información incorporada en el documento.
La Web Semántica puede mejorar la automatización de la mayoría
de las tareas de procesamiento de la información, que en la actualidad
lleva a cabo el individuo.
La información contenida, por ejemplo, productos y servicios, en las
aplicaciones de comercio electrónico deben ser conceptualizadas a partir
de ontologías que proporcionan la descripción y la jerarquía
de la información que se utiliza, así como sus relaciones: descripción
de las clases y subclases de productos junto con las cualidades del producto
asociadas.
El interés del comercio electrónico reside en permitir un mercado
electrónico global en donde las empresas de cualquier tamaño y
localización geográfica pueden resolver y dirigir los negocios
intercambiando información formalmente estructurada en base a lenguajes
de marcado y ontologías. Asimismo será necesario modelar progresivamente
aplicaciones ontológicas que favorezcan el intercambio eficiente de información.
La primera generación de ontologías aplicables al comercio electrónico
proporciona un sistema de especificaciones que permiten modelar el marco donde
se desarrolla el comercio electrónico. La segunda generación se
centra en desarrollar los nuevos modelos que favorecerán la interoperabilidad
requerida en el intercambio de información dinámico y complejo
incorporado al comercio electrónico.
Por ejemplo, si un usuario desea planificar un viaje a un destino turístico,
deberá acceder manualmente a todas las páginas que contienen la
información que necesita para su viaje: en primer lugar, deberá
reservar el vuelo; posteriormente, deberá acceder a la página
de una cadena hotelera y efectuar la reserva de plaza; y por último,
consultará los horarios y líneas del transporte local en la página
del ayuntamiento de la ciudad destino. Por tanto, con la Web actual no hay manera
de que se pueda automatizar este proceso. Porque un agente encontraría
la cadena de caracteres “53” y no sabría diferenciar si es
el número de la calle o el precio de la habitación. El usuario
desearía poder especificar sus preferencias de viaje a un programa (agente
inteligente) que llevara a cabo todo el proceso sin intervención humana,
y evitar perder horas navegando y accediendo de forma manual a las páginas
que necesita. Esto que no es posible ahora, será posible con la Web del
futuro que se ha bautizado como Web Semántica.
- Sistemas de información geográfica (GIS): El
intercambio de información entre diferentes GIS a veces falla debido
a confusiones en el significado de términos.
(http://www.ii.uam.es/~castells/docencia/semanticweb/trabajos/ui-99ws.pdf).
Un ejemplo de GIS que usa un traductor semántico es el Feature manipulation
Engine (FME) desarrollado por el gobierno canadiense
- Intermediación de derechos de propiedad intelectual:
La Web Semántica actúa también como estructura para gestionar
el enorme mercado de productos digitales. Señalamos la iniciativa MARS
como ejemplo de este uso. Cada documento digital contendrá un número
único, el URN, que funciona como una especie de marca de agua, que será
siempre visible y comprensible para los motores como un metadato más.
Éste número servirá para el control de las transacciones
de productos con copyright por parte de los vendedores.
(http://www.semanticweb.org/SWWS/program/full/paper15.pdf).
- Mejora de los resultados en la recuperación de información
audiovisual: Para ello se requiere el desarrollo de estándares
específicos para este tipo de datos. Por ejemplo el MPEG-7 (http://archive.dstc.edu.au/RDU/staff/jane-hunter/semweb/paper.html).
Existen proyectos de reconocimiento de imágenes por parte de máquinas,
que pueden tener prometedores resultados en la recuperación de información
multimedia, aunque también en muchos otros ámbitos, como por ejemplo,
la medicina.
El proyecto FUSION (http://metadata.net/sunago/fusion.htm) tiene como objetivos
desarrollar un esquema XML que defina los atributos de las imágenes (metadatos).
Además utilizan un software para el procesamiento de imágenes.
Asimismo hay aplicaciones de reconocimiento de cadenas de sonido y motores de
búsqueda de canciones, como Song Surfer de MTG-IUA UPF. Más complicado
es idear sistemas que permitan estrategias de búsqueda no basadas en
texto.
- Servicios móviles dependientes del contexto (Mobile Context-
Aware services): Las aplicaciones de la Web Semántica para los
servicios en Internet estarán también disponibles para los dispositivos
móviles. Éstas fueron desarrolladas en principio por el Departamento
de Defensa de EE.UU., pero tienen también bastantes aplicaciones civiles.
(http://wwww.daml.org/2003/01/iow/cmu2/).
- Para el control de datos de empresas: A modo de páginas
amarillas, son directorios de empresas estructurados de forma comprensible para
las máquinas. Esto facilita las relaciones y los negocios entre unas
empresas y otras. Por ejemplo UDDI, que es una propuesta de IBM, Microsoft y
Ariba.
- Aplicaciones educativas: El estudiante, una vez conectado, seleccionará
una serie de temas de una ontología general. El sistema organizará
un curso personalizado y adaptado de forma automática según el
perfil del estudiante. Los profesores que así lo deseen podrán
convertirse en “recursos de aprendizaje”. El sistema podrá
también agrupar a estudiantes similares, o representar los resultados
de cada uno en un formato estándar y convertir cada uno de sus perfiles
en un registro de una base de datos de currícula, accesible en las condiciones
de privacidad requeridas.
- Manejo de datos matemáticos: La WS también puede acoger
los contenidos matemáticos, o al menos así lo creen los que desarrollan
lenguaje de marcado para matemáticas (MathML).
- Adaptación de la web a los discapacitados: Mediante la mejora
de las herramientas de lectura, escritura y traducción y la extracción
del contenido de las representaciones gráficas.
Otras aplicaciones futuras (extraídas de textos científicos
y no de novelas de ciencia-ficción):
- Cámaras que detecten agresiones de forma automática (Kemp, TNO-FEL).
- La casa domótica. El frigorífico se comunica con el supermercado
y el microondas con el fabricante del producto congelado que vamos a calentar
para averiguar el tiempo de cocción.
- Tu coche avisará a las personas implicadas de que llegarás tarde
porque estás en un atasco (el propio atasco es un nodo de la Web Semántica).
Asimismo, si sufres un accidente, tu coche avisará a los servicios de
urgencias, etc.
Según Ronald Poell, la Web Semántica es sólo una estructura,
un pegamento que mejorará diferentes tecnologías ya existentes,
como por ejemplo, reconocimiento del habla, extracción de contenido visual,
búsquedas no basadas en texto, resumen automático, traducción
automática. Probablemente la WS nos proporcionará nuevas tecnologías
que aún no podemos ni imaginar.
6. La Web Semántica hoy
Los resultados alcanzados hasta ahora hacia la realización
de la web semántica son muy preliminares si se mira desde la óptica
más ambiciosa, la de la adopción universal de la web semántica.
Se ha avanzado mucho con las herramientas, los estándares y la infraestructura
necesarios para el despliegue de la web semántica, y se han desarrollado
proyectos y experiencias piloto para poner a prueba las herramientas y las ideas.
En este punto, el desarrollo de aplicaciones reales basadas en esta tecnología
se ha identificado como una realización necesaria para que la web semántica
prospere [Haustein 2002].
Existe un gran interés desde el entorno corporativo, el sector público
y el mundo académico por hacer de la web semántica una realidad,
ya que se piensa que puede ser una pieza importante para el progreso de la sociedad
de la información. Las grandes agencias de financiación pública
(programas marco EU-IST en Europa, DARPA en EE.UU.) incluyen áreas prioritarias
específicas dedicadas a la web semántica, y están invirtiendo
grandes presupuestos en proyectos de investigación y desarrollo en este
campo (la última llamada del VI Programa Marco ha destinado más
de 60.000 millones de euros al área “Semantic-based Knowledge Systems”
para los próximos cuatro años).
Las principales empresas (IBM, Microsoft, Sun, Oracle, BEA,
SAP, HP…) están participando activamente en el desarrollo de los
estándares y tecnologías.
La web semántica se ha convertido en un área de investigación
de moda en los centros de investigación de todo el mundo, entre ellos
el MIT, la Universidad de Stanford, la Universidad de Maryland, la Universidad
de Innsbruck (Austria), la Universidad de Karlsruhe (Alemania), la Universidad
de Manchester, la Open University en el Reino Unido, por citar tan sólo
algunos de los grupos más fuertes. También en la Universidad Autónoma
de Madrid se están llevando a cabo proyectos en esta área, y se
ha formado una línea de investigación y desarrollo en web semántica,
47 de la que participa el autor de este artículo. En pocos años
se ha consolidado una comunidad investigadora considerable, de cuyo reflejo
cabe destacar un gran congreso internacional que se celebra con carácter
anual (International Semantic Web Conference 48 ), y revistas como el Journal
of Web Semantics, 49 o el área The Semantic Web de Electronic Transactions
on Artificial Intelligence 50 (ETAI). Es muy de destacar así mismo el
apoyo y el importante papel del W3C en el proyecto de la web semántica,
con la creación de grandes y muy activos grupos de trabajo para el desarrollo
de esta área, y muy en especial liderando el esfuerzo de estandarización
de lenguajes y tecnologías específicas para la web semántica.
Aún queda mucho trabajo por hacer. Se necesita crear más y mejor tecnología e infraestructura, y más aún, desarrollar aplicaciones reales que pongan en práctica los principios de la web semántica, que pueblen la web con ontologías, y que hagan que la web semántica adquiera la masa crítica imprescindible para hacerse realidad. En espera de que se alcance esta meta y al margen de ese debate, se han desarrollado ideas muy aprovechables a niveles específicos, y se han abierto nuevos campos para la innovación, suficientemente interesantes, en opinión de este autor, para que merezca la pena involucrarse en esta área.
7. Perspectivas de futuro
Parece factible el funcionamiento de Agentes Electrónicos
que combinen información de diferentes fuentes (páginas web),
haciendo interpretaciones y dando soluciones elaboradas a partir de las mismas.
Si se consiguen lenguajes de marcado con mayor expresividad para representar
los conocimientos que contienen las ontologías, se alcanzarán
metas significativas, como sería el fomento de las transacciones entre
empresas por comercio electrónico.
La perspectiva de futuro que todos desearíamos, simplificada en que los
agentes web no sólo encontrarán la información de forma
precisa, sino que podrán realizar inferencias automáticamente
buscando información relacionada con la que se encuentra situada en las
páginas, y con los requerimientos de la consulta indicada por el usuario,
no se ve cercana.
Parece muy lejos el día en que de forma mayoritaria los contenidos de
la web tengan significado semántico, y el entendimiento de los numerosos
matices que la inteligencia humana procesa, hoy por hoy, es lago inalcanzable
para las máquinas.
De momento no hay un sistema para que los ordenadores interpreten la información
y tomen decisiones adaptándolas al contexto. Las posibilidades a corto
y medio plazo de la WS son muy reducidas. Una cosa es que se trate de un objetivo
que vale la pena perseguir y otro que sea factible.
Pero pese a todo lo dicho hasta aquí, el objetivo de la Web Semántica
es magnífico, producirá importantes avances en algunos o en todos
los terrenos relacionados con la representación y el acceso al conocimiento
y por lo tanto es importante apoyar esa perspectiva de futuro.
8. Bibliografía
· Arroyo Menéndez, David y García Cataño,
Carlina. “Biblioteca Digital y Web Semántica”, 2002. En:
http://www.sindominio.net/biblioweb/telematica/bibdigwebsem.htm.
[última consulta: 19 - 04 - 2005].
· Lozano Tello, A. “Ontologías en la Web
Semántica”.
I Jornadas de Ingeniería Web´01. www.informandote.com/jornadasIngWEB/articulos/jiw02.pdf
[última consulta: 14-05-2005].
· Berners-Lee, T., Hendler, J., Lassila, O. “The
Semantic Web”. Scientific American. Mayo 2001, vol. 284, nº 5, p.
34-43.
· Ding, Y., ET AL. “The semantic web: yet another hip?”.
Data & Knowledge Engineering. 2002, vol. 41, nº 2002, p. 205-227.
· Codina, Ll. “La Web Semántica: una visión crítica”.
El profesional de la información. Marzo-abril 2003, vol. 12, nº
2, p. 149-152.
· Lu, S., Dong, M., Fotouhi, F. “The Semantic Web: opportunities
and challenges for next-generation Web applications”. Informtaion Research.
July 2002, vol. 7, nº 4.
· Brooks, T.A. “The Semantic Web, universalist
ambition and some lessons from librarianship”. Information Research. July
2002, vol. 7, nº 4.
· World Wide Web Consortium: W3C. EE.UU.: W3C® (MIT, ERCIM, Keio),
Copyright © 1994-2005. http://www.w3.org.
[última consulta: 2-05-2005].
· Berners-lee, T. “Semantic web road map”. En: IW3C Design
Issues. Cambridge, Massachusetts: W3C, 1998. http://www.w3.org/DesignIssues/Semantic.html
. [última consulta: 2-05-2005].
· Castells, Pablo y Saiz, Francisco. “Tecnologías de modelado y gestión del conocimiento en la Web Semántica” . Madrid: Universidad Autónoma de Madrid, Escuela Técnica Superior de Informática, 2001. http://www.ii.uam.es/~castells/docencia/semanticweb/. [última consulta: 2-05-2005].
· Castells, Pablo. “Aplicación de técnicas de la Web Semántica”. Madrid: Universidad Autónoma de Madrid, 2002. http://giig.ugr.es/~mgea/coline02/Articulos/pcastells.pdf [última consulta: 2-05-2005].
· Robledano Esteban, Luis Fernando. “Gestión del Conocimiento en la Web Semántica”. En: http://www.iit.upco.es/~luisf/index.html [última consulta: 25-04-2005].
· URL: https://listas.hispalinux.es/pipermail/web-semantica-ayuda/2003-April/000013.html [última consulta: 25-04-2005].
· URL: http://www.w3c.es/divulgacion/guiasbreves/WebSemantica [última consulta: 25-04-2005].
· URL: http://www.w3.org/2001/sw/ [última consulta: 25-04-2005].
· URL: http://www.w3.org/TR/owl-features/ [última consulta: 25-04-2005].
· URL: http://www.w3.org/RDF [última consulta: 25-04-2005].
· URL: http://www.w3.org/RDF/FAQ [última consulta: 25-04-2005].
· URL: http://www.w3c.es/Traducciones/es/SW/2005/owlfaq [última consulta: 25-04-2005].
· URL: http://www.w3.org/2001/sw/WebOnt/impls [última consulta: 25-04-2005].
· URL: http://www.schemaweb.info/schema/BrowseSchema.aspx [última consulta: 25-04-2005].
· URL: http://pear.cs.umbc.edu/swoogle/ [última consulta: 25-04-2005].